이 글은 RL4CO 라이브러리 중 PDP(Pickup and Delivery Problem) 문제에 대한 알고리즘 코드를 구현하고 리뷰한 내용이다. 기본 소스 코드는 다음 Github 주소를 참고하였다.
http://RL4CORL4CO" target="_blank" rel="noopener" data-mce-href="http://RL4CO">http://RL4CO
GitHub - ai4co/rl4co: A PyTorch library for all things Reinforcement Learning (RL) for Combinatorial Optimization (CO)
A PyTorch library for all things Reinforcement Learning (RL) for Combinatorial Optimization (CO) - ai4co/rl4co
github.com
1. 필요한 라이브러리 로드
!pip install tensordict
!pip install torchrl
!pip install rl4co
from typing import Optional
import matplotlib.pyplot as plt
import torch
from torch import Tensor
from tensordict.tensordict import TensorDict
from torchrl.data import (
BoundedTensorSpec,
CompositeSpec,
UnboundedContinuousTensorSpec,
UnboundedDiscreteTensorSpec,
)
from rl4co.envs.common.base import RL4COEnvBase
from rl4co.utils.ops import gather_by_index, get_tour_length
2. TensorDict 클래스 생성
- Pytorch Tensor를 다루기 위한 TensorDict 클래스 생성, 기본 딕셔너리 'dict' 상속
- __init__ : 클래스 생성자, 'data'와 'batch_size'를 초기 파라미터로 받음
- update: 'update' 메서드 오버라이딩
- to (self, device): 모든 텐서 값들을 지정된 디바이스로 이동 (CPU, GPU)
- detach(self): 딕셔너리 내의 모든 텐서들로부터 연산 그래프 분리하고 딕셔너리의 key-value 값이 텐서인 경우 해당 텐서 분리 후 다시 딕셔너리에 저장
- cpu(self): 딕셔너리 내의 모든 텐서를 CPU로 이동
- is_empty: 딕셔너리가 비어있으면 True, 그렇지 않으면 False
class TensorDict(dict):
def __init__(self, data=None, batch_size=None):
super().__init__(data if data is not None else {})
self.batch_size = batch_size
def update(self, *args, **kwargs):
super().update(*args, **kwargs)
return self
def to(self, device):
for key, value in self.items():
if isinstance(value, Tensor):
self[key] = value.to(device)
return self
def detach(self):
for key, value in self.items():
if isinstance(value, Tensor):
self[key] = value.detach()
return self
def cpu(self):
return self.to('cpu')
def is_empty(self):
return len(self) == 0
3. RL4COEnvBase 클래스 생성
pass를 사용하여, 클래스 자체로서의 동작은 정의하지 않음, but, 자식 클래스의 피상속 클래스로 사용 예정
class RL4COEnvBase:
def __init__(self, **kwargs):
pass
4. PDPEnv 클래스 생성
PDP 환경은 1개의 창고와 n개의 노드로 총 n+1 개의 경유지로 구성되어 있다.
n개의 노드는 다시 각각 n2개의 픽업 노드와 배송지 노드로 구성된다.
▶ 목적: 창고에서 시작하여 모든 픽업 노드와 배송지 노드를 최단 경로로 순회
▶ 제약조건 : Agent는 배송지 노드를 순회하기 전에 모든 픽업 노드를 순회할 것
- RL4COEnvBase 객체를 상속받아 생성
- __init__ : 생성자
- _step :
- 현재 행동 'action'을 받아 환경의 상태 업데이트
- 'available' 배열에서 방문한 노드를 방문 불가능하게 설정
- 모든 노드가 방문되면 done = True
- reward: get_reward 함수를 통해 보상 계산
- _reset : PDPEnv의 인스턴스 상태 초기화 (매 epoch 마다)
- batch_size : 배치 크기 확인, 설정. default는 __init__에서 정한 self.batch_size
- td: 상태를 나타내는 'TensorDict' 인스턴스. None이면, self.generate_data로 새로운 데이터 생성
- locs: 모든 위치 정보를 포하하는 텐서 생성. torch.cat은 depot을 첫번째 위치로 설정
- to_deliver: 픽업과 딜리버리 위치를 나타내는 boolean 텐서 생성
- available: 초기 상태는 모두 True, 방문할 때마다 False로 바꿔줌
- action_mask: Agent가 방문 가능한 위치. 초기 상태는 depot를 제외한 모든 위치 방문 불가능이므로 depot를 제외한 나머지 위치는 False.
- make_spec : 환경이 관찰하고, 행동하고, 보상을 받고, 완료될 때의 규격 설정을 통해 에이전트가 수행할 수 있는 행동, 보상, 에피소드 종료 조건을 명확히 규정
- self.observation_spec: 관찰 규정
- 'locs' : 위치 정보, 각 위치는 2D 좌표로 self.min_loc과 self.max_loc 사이에 있음
- 'current_node' : 현재 노드를 나타내는 정수
- 'to_deliver' : 각 노드가 딜리버리 노드인지 나타냄
- 'i" : epoch 횟수 추적
- action_mask: 가능한 행동들을 나타내는 mask로 에이전트가 해당 노드 방문 가능 여부를 boolean 값으로 표현함
- self.action_spec : 행동 규정
- 에이전트가 취할 수 있는 행동에 대한 사양 설정
- 행동은 0부터 self.num_loc + 1 범위 내의 정수값, 다음 위치의 인덱스를 의미
- self.reward_spec : 보상 규정, 연속적인 값, 제한 없음
- self.done_spec : 에피소드 종료 규정, boolean 텐서
- self.observation_spec: 관찰 규정
- get_reward : @staticmethod, 에이전트 행동에 대한 보상 계산, 이동거리에 따른 보상 계산
- 첫번째 Assert 문: 모든 에피소드가 depot에서 시작하는지 확인
- 두번째 Assert 문: 에이전트가 모든 노드를 방문했는지 확인
- 세번째 Assert 문: 방문 시간 순서가 픽업 지점이 딜리버리 지점보다 먼저인지 확인
- get_tour_length : 총 이동거리 계산, 이를 통해 보상을 계산
- generate_data : PDPEnv 환경에서 배치 크기에 따라 위치 데이터를 초기화하여 새로운 데이터를 생성, 2D 좌표 형태로 생성한다.
- batch_size:
- 함수에 전달된 batch_size가 정수라면, 이를 리스트로 변환
- batch_size가 이미 리스트라면, 그대로 사용
- locs_with_depot:
- torch.FloatTensor로 지정된 배치 크기와 위치 수와 2차원 공간 좌표를 위한 차원을 갖는 텐서 생성
- .uniform : self.min_loc와 self.max_loc 사이의 균일한 분포에서 모든 좌표 값들 무작위 선택
- .to(self.device): 생성된 텐서를 device로 이동
- TensorDict 반환
- 'locs': depot를 제외하고 나머지 모든 위치 좌표 저장, 첫번째 위치를 제외한 모든 위치 좌표 슬라이싱
- 'depot': depot 위치 좌표 저장
- batch_size:
- render : @staticmethod, 현재 상태와 에이전트의 행동 시각화
- TensorDict 준비: 'td' 객체에서 .detach().cpu()를 호출하여 연산 그래프로부터 분리하고, CPU로 이동
- 배치 처리: td.batch_size != torch.Size([]) 조건을 사용하여 배치 처리된 데이터인지를 확인
- 변수 할당: init_deliveries, delivery_locs, pickup_locs, depot_loc 변수를 할당하여 각 위치 유형(픽업, 딜리버리, 디포)에 따라 분리
- 도식화
- depot는 녹색 사각형 ■
- 픽업 위치는 빨간색 삼각형 ▲
- 딜리버리 위치는 파란색 역삼각형 ▼
- 에이전트의 이동 경로는 검은색 선과 화살표로 표시되어, 경로를 따라 이동하는 순서
class PDPEnv(RL4COEnvBase):
name = "pdp"
def __init__(
self,
num_loc: int = 20,
min_loc: float = 0,
max_loc: float = 1,
td_params: TensorDict = None,
device: torch.device = torch.device('cpu'),
**kwargs,
):
super().__init__(**kwargs)
self.num_loc = num_loc
self.min_loc = min_loc
self.max_loc = max_loc
self.device = device
self._make_spec(td_params)
# 상태 업데이트
def _step(self, td: TensorDict) -> TensorDict:
current_node = td["action"].squeeze(1) # [batch_size, 1] -> [batch_size]
# 'available'에서 현재 노드 방문 처리
# Boolean indexing을 사용하여 'available'에서 현재 노드를 False로 설정
batch_indices = torch.arange(td["available"].size(0), device=self.device) # 배치 내 각 인덱스
td["available"][batch_indices, current_node] = False
# 모든 위치 방문 시 'done' 설정
done = ~td["available"].any(dim=1) # 모든 노드가 방문되었는지 확인
# 'reward'는 외부에서 계산되므로 여기서는 0으로 설정
# 실제 사용 시 필요에 따라 적절한 보상 계산 로직을 추가
reward = torch.zeros_like(done, dtype=torch.float)
# 상태 업데이트
td.update({
"current_node": current_node.unsqueeze(-1), # 차원을 [batch_size, 1]로 복원
"available": td["available"],
"reward": reward,
"done": done,
})
return td
def _reset(self, td: Optional[TensorDict] = None, batch_size=None) -> TensorDict:
if batch_size is None:
batch_size = self.batch_size if td is None else td.batch_size
if td is None or td.is_empty():
td = self.generate_data(batch_size=batch_size)
#self.to(td.device)
locs = torch.cat((td["depot"][:, None, :], td["locs"]), -2)
# Pick is 1, deliver is 0 [batch_size, graph_size+1], [1,1...1, 0...0]
to_deliver = torch.cat(
[
torch.ones(
*batch_size,
self.num_loc // 2 + 1,
dtype=torch.bool,
device=self.device,
),
torch.zeros(
*batch_size, self.num_loc // 2, dtype=torch.bool, device=self.device
),
],
dim=-1,
)
# Cannot visit depot at first step # [0,1...1] so set not available
available = torch.ones(
(*batch_size, self.num_loc + 1), dtype=torch.bool, device=self.device
)
action_mask = ~available.contiguous() # [batch_size, graph_size+1]
action_mask[..., 0] = 1 # First step is always the depot
# Other variables
current_node = torch.zeros(
(*batch_size, 1), dtype=torch.int64, device=self.device
)
i = torch.zeros((*batch_size, 1), dtype=torch.int64, device=self.device)
return TensorDict(
{
"locs": locs,
"current_node": current_node,
"to_deliver": to_deliver,
"available": available,
"i": i,
"action_mask": action_mask,
},
batch_size=batch_size,
)
def _make_spec(self, td_params: TensorDict):
"""Make the observation and action specs from the parameters."""
self.observation_spec = CompositeSpec(
locs=BoundedTensorSpec(
low=self.min_loc,
high=self.max_loc,
shape=(self.num_loc + 1, 2),
dtype=torch.float32,
),
current_node=UnboundedDiscreteTensorSpec(
shape=(1),
dtype=torch.int64,
),
to_deliver=UnboundedDiscreteTensorSpec(
shape=(1),
dtype=torch.int64,
),
i=UnboundedDiscreteTensorSpec(
shape=(1),
dtype=torch.int64,
),
action_mask=UnboundedDiscreteTensorSpec(
shape=(self.num_loc + 1),
dtype=torch.bool,
),
shape=(),
)
self.action_spec = BoundedTensorSpec(
shape=(1,),
dtype=torch.int64,
low=0,
high=self.num_loc + 1,
)
self.reward_spec = UnboundedContinuousTensorSpec(shape=(1,))
self.done_spec = UnboundedDiscreteTensorSpec(shape=(1,), dtype=torch.bool)
@staticmethod
def get_reward(td, actions) -> TensorDict:
# assert (actions[:, 0] == 0).all(), "Not starting at depot"
assert (
torch.arange(actions.size(1), out=actions.data.new())
.view(1, -1)
.expand_as(actions)
== actions.data.sort(1)[0]
).all(), "Not visiting all nodes"
visited_time = torch.argsort(
actions, 1
) # index of pickup less than index of delivery
assert (
visited_time[:, 1 : actions.size(1) // 2 + 1]
< visited_time[:, actions.size(1) // 2 + 1 :]
).all(), "Deliverying without pick-up"
# Gather locations in the order of actions and get reward = -(total distance)
locs_ordered = gather_by_index(td["locs"], actions) # [batch, graph_size+1, 2]
return -get_tour_length(locs_ordered)
def generate_data(self, batch_size) -> TensorDict:
batch_size = [batch_size] if isinstance(batch_size, int) else batch_size
# Initialize the locations (including the depot which is always the first node)
locs_with_depot = (
torch.FloatTensor(*batch_size, self.num_loc + 1, 2)
.uniform_(self.min_loc, self.max_loc)
.to(self.device)
)
return TensorDict(
{
"locs": locs_with_depot[..., 1:, :],
"depot": locs_with_depot[..., 0, :],
},
batch_size=batch_size,
)
@staticmethod
def render(td: TensorDict, actions=None, ax=None):
import matplotlib.pyplot as plt
markersize = 8
td = td.detach().cpu()
# if batch_size greater than 0 , we need to select the first batch element
if td.batch_size != torch.Size([]):
td_extracted = {key: value[0] for key, value in td.items()}
else:
td_extracted = td
# 추출된 TensorDict 사용
td = td_extracted
# Variables
init_deliveries = td["to_deliver"][1:]
delivery_locs = td["locs"][1:][~init_deliveries.bool()]
pickup_locs = td["locs"][1:][init_deliveries.bool()]
depot_loc = td["locs"][0]
actions = actions if actions is not None else td["action"]
fig, ax = plt.subplots()
# Plot the actions in order
for i in range(len(actions)):
from_node = actions[i]
to_node = (
actions[i + 1] if i < len(actions) - 1 else actions[0]
) # last goes back to depot
from_loc = td["locs"][from_node]
to_loc = td["locs"][to_node]
ax.plot([from_loc[0], to_loc[0]], [from_loc[1], to_loc[1]], "k-")
ax.annotate(
"",
xy=(to_loc[0], to_loc[1]),
xytext=(from_loc[0], from_loc[1]),
arrowprops=dict(arrowstyle="->", color="black"),
annotation_clip=False,
)
# Plot the depot location
ax.plot(
depot_loc[0],
depot_loc[1],
"g",
marker="s",
markersize=markersize,
label="Depot",
)
# Plot the pickup locations
for i, pickup_loc in enumerate(pickup_locs):
ax.plot(
pickup_loc[0],
pickup_loc[1],
"r",
marker="^",
markersize=markersize,
label="Pickup" if i == 0 else None,
)
# Plot the delivery locations
for i, delivery_loc in enumerate(delivery_locs):
ax.plot(
delivery_loc[0],
delivery_loc[1],
"b",
marker="v",
markersize=markersize,
label="Delivery" if i == 0 else None,
)
# Setup limits and show
ax.set_xlim(-0.05, 1.05)
ax.set_ylim(-0.05, 1.05)
5. 환경 학습하기
- def get_tour_length() : 주어진 경로의 총 거리 계산
- def calculate_total_distance : 주어진 위치와 행동 시퀀스에 기반하여 총 이동거리 계산
- best_distance, best_reward: 찾아낸 최단거리와 최대 보상 기록, 각각 무한대와 음의 무한대로 초기화
import torch
import random
from tqdm import tqdm..
# get_tour_length 함수 가정 구현
def get_tour_length(locs_ordered):
# 각 지점 간의 유클리디언 거리 계산을 위한 함수로 가정합니다.
tour_length = 0.0
for i in range(1, len(locs_ordered)):
tour_length += torch.norm(locs_ordered[i] - locs_ordered[i - 1]).item()
return tour_length
# 각 에폭마다 최단 경로 탐색 및 기록
best_reward = -float('inf') # 최대 보상을 찾기 위한 변수 초기화
def calculate_total_distance(locations, actions):
total_distance = 0.0
prev_loc = locations[0] # Start from the depot
for action in actions:
current_loc = locations[action] # Get the current location
total_distance += torch.norm(current_loc - prev_loc).item() # Calculate the distance
prev_loc = current_loc # Update the previous location
total_distance += torch.norm(prev_loc - locations[0]).item() # Return to the depot
return total_distance
num_locations = 10
num_epochs = 10000
best_distance = float('inf')
best_path = None
env = PDPEnv(num_loc=num_locations)
for epoch in tqdm(range(num_epochs)):
td_reset = env._reset(env.generate_data(batch_size=1))
# Initialize the tour with the depot as the starting point
actions = [0] # Start at the depot
pickup_indices = list(range(1, num_locations // 2 + 1))
actions += random.sample(pickup_indices, len(pickup_indices))
# 각 픽업 지점에 대한 딜리버리 지점을 방문합니다.
delivery_indices = list(range(num_locations // 2 + 1, num_locations + 1))
actions += random.sample(delivery_indices, len(delivery_indices))
# Apply actions, making sure to start at the depot
for action_value in actions:
action_tensor = torch.tensor([[action_value]]) # Keep action as it is
td_reset = env._step(td_reset.update({"action": action_tensor}))
# Calculate the total distance for the tour
current_distance = calculate_total_distance(td_reset['locs'].reshape(-1,2), actions)
"""여기서 reshape(-1,2)를 해주는 이유는 'loc'가 (x,y)좌표 형태이기 때문이다"""
# Save the best tour found so far
if current_distance < best_distance:
best_distance = current_distance
best_path = actions
locs_ordered = gather_by_index(td_reset['locs'], torch.tensor(best_path).unsqueeze(0))
best_reward = -get_tour_length(locs_ordered)
env.render(env._reset(env.generate_data(batch_size=1)), best_path)
print(f"Best distance: {best_distance}")
print(f"Best path: {best_path}")
print(f"Best reward: {best_reward}")
[결과 시각화]
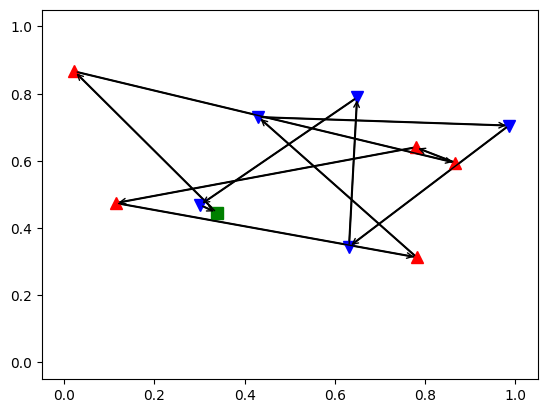
6. 부록
원본에서는 _step 메서드를 사용할 때 @staticmethod를 사용하였는데, 굳이 그럴 이유가 없을 거 같아서 내가 실습한 코드에서는 그 부분을 제거하였다.
<<원본>>
@staticmethod
def _step(td: TensorDict) -> TensorDict:
current_node = td["action"].unsqueeze(-1)
num_loc = td["locs"].shape[-2] - 1 # except depot
#Pickup and delivery node pair of selected node
new_to_deliver = (current_node + num_loc // 2) % (num_loc + 1)
#Set available to 0 (i.e., we visited the node)
available = td["available"].scatter(
-1, current_node.expand_as(td["action_mask"]), 0
)
to_deliver = td["to_deliver"].scatter(
-1, new_to_deliver.expand_as(td["to_deliver"]), 1
)
#Action is feasible if the node is not visited and is to deliver
#action_mask = torch.logical_and(available, to_deliver)
action_mask = available & to_deliver
We are done there are no unvisited locations
done = torch.count_nonzero(available, dim=-1) == 0
#The reward is calculated outside via get_reward for efficiency, so we set it to 0 here
reward = torch.zeros_like(done)
Update step
td.update(
{
"current_node": current_node,
"available": available,
"to_deliver": to_deliver,
"i": td["i"] + 1,
"action_mask": action_mask,
"reward": reward,
"done": done,
}
)
return td
▶ calculate_total_distance 와 get_tour_length 함수의 차이점:
- calculate_total_distance는 행동 시퀀스(actions)와 위치 정보(locations)를 모두 사용.
- calculate_total_distance 의 목적은 특정 행동 시퀀스에 대한 경로의 총 이동 거리를 계산하는 것
- 반면, get_tour_length는 정렬된 위치 정보만을 입력으로 받음.
- get_tour_length는 특정 행동 시퀀스를 고려하지 않고 위치 데이터만을 기반으로 계산
[내 실습 코드]
PDP" target="_blank" rel="noopener" data-mce-href="http://PDP">http://PDP
GitHub - taekyounglee1224/Reinforcement-Learning
Contribute to taekyounglee1224/Reinforcement-Learning development by creating an account on GitHub.
github.com
'산업공학 > Reinforcement Learning' 카테고리의 다른 글
| [강화학습] Dynamic Programming (동적 계획법) (0) | 2025.03.31 |
|---|---|
| [강화학습] 4. Bellman Equation (1) | 2024.03.20 |
| [강화학습] 3. Reward and Policy (0) | 2024.03.20 |
| [강화학습] 2. Markov Decision Process (MDP) (1) | 2024.02.21 |
| [강화학습] 1. Introduction to Reinforcement Learning (0) | 2024.02.06 |