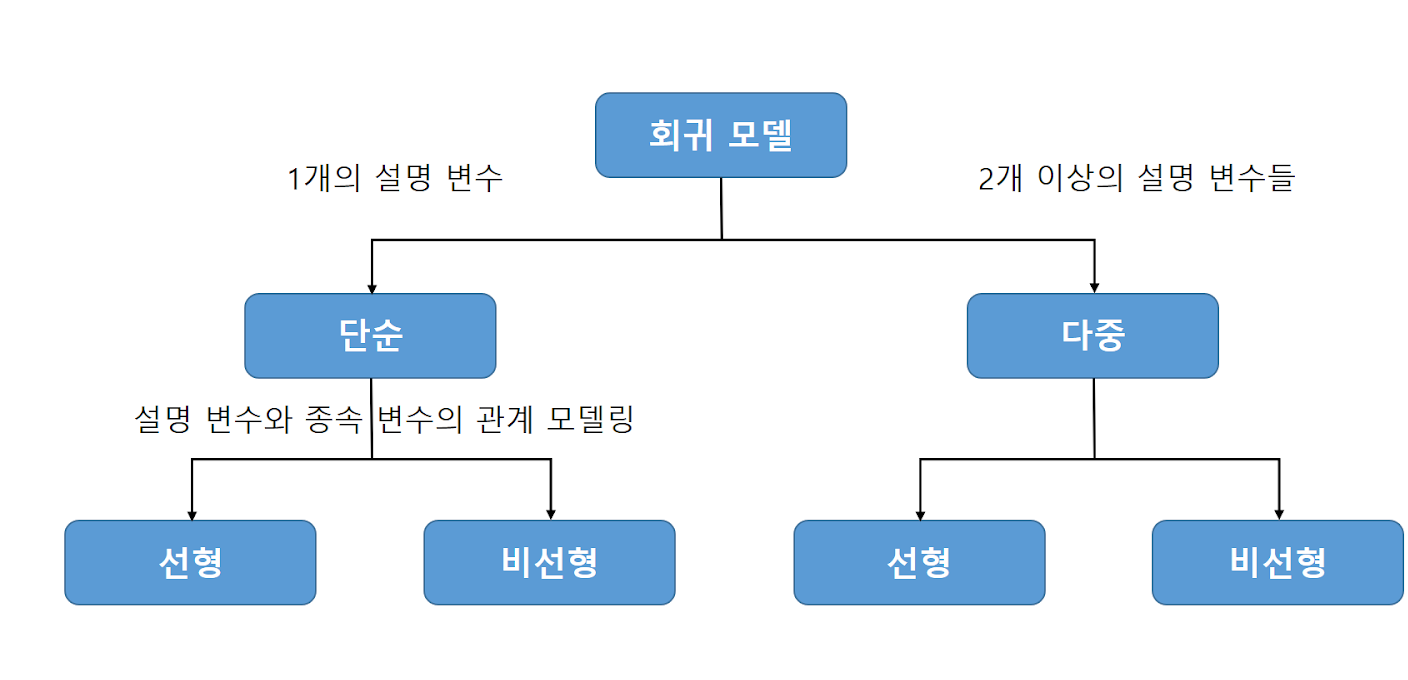
회귀란?회귀라는 뜻은 어떤 지점으로 돌아간다는 뜻이다. 수많은 데이터들을 수집해보면 어떤 점, 즉 평균으로 돌아가게 되는데, 그 점들을 이어보면 하나의 직선을 이루게 되고 이것을 회귀 직선이라고 한다. 그리고 이 회귀 직선을 식으로 나타낸 것을 회귀식이라고 한다. $$y = w_0 + w_1x_1 + w_2x_2 + \cdots + w_nx_n + \epsilon$$ $y$: 독립변수의 영향을 받아 값이 변화하는 수로, 종속변수라 하고 주로 분석하고자 하는 대상이 된다.$x_i$: 다른 변수에 영향을 받지 않고 독립적으로 변화하는 수로, 독립변수라고 한다.$w_i$: 독립변수가 1 변할 때, 종속변수가 얼마나 변하는지 나타내는 수로, 회귀계수라고 부른다.$\epsilon$: 실제값과 회귀값의 차이에 따른..