사이킷런$($Scikit-Learn$)$ 라이브러리
사이킷런 라이브러리는 파이썬 기반 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다. 다양한 머신러닝 알고리즘과 API 등을 제공하기 때문에 비교적 쉽고 편리하게 사용할 수 있다는 장점 때문에 데이터 분석가들 사이에서 인기가 있다.
사이킷런 머신러닝 워크플로우
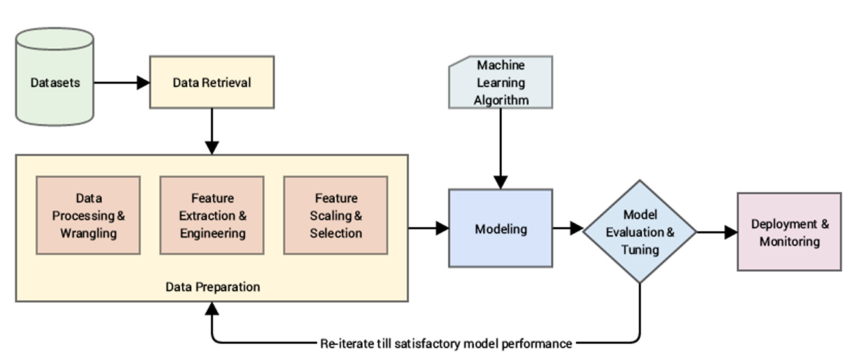
- 데이터 수집 : 필요한 데이터를 모으고 저장하는 단계
- 데이터 전처리 : 데이터를 분석에 적합한 형태로 가공하는 단계, $($이상치 제거, 결측치 제거, 정규화, 인코딩 등$)$
- 모델 훈련 및 학습 : 전처리된 데이터를 활용해 알고리즘을 학습시키는 단계, 필요에 따라 하이퍼 파라미터 조정
- 모델 성능 평가 : 학습된 모델의 성능을 평가하는 단계, 정확도, 정밀도, 재현율, F1-score 등의 지표들을 활용
사이킷런 기반의 프레임워크
1. fit, predict 메서드:
- fit$($$)$: 모델을 학습
- predict$($$)$: 학습된 모델을 활용하여 target 예측
- 분류와 회귀에 사용
- 사용법 예시:
# 회귀 분석에서의 사용 예시
lr = LinearRegression()
lr.fit(X_train, y_train)
pred = lr.predict(X_test)
2. transform 메서드:
- 데이터의 차원 변환, 클러스터링, 피처 추출 담당
- 사용법 예시:
#표준 정규화 사용 예시
scaler = StandardScaler()
scaler.fit(data)
scaler_data = scaler.transform(data)
3. 사이킷런의 주요 모듈
| 모듈 이름 | 내장 메서드 예시 |
| sklearn.model_selection | train_test_split, cross_val_score, GridSearchCV, KFold |
| sklearn.preprocessing | StandardScaler, MinMaxScaler |
| sklearn.metrics | accuracy_score, mean_squared_error, f1_score |
#보통 데이터를 불러올 때 다음과 같이 라이브러리와 함께 로드한다
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy, f1_score # 이런 식으로 한 번에 여러 개 메서드 소환 가능
4. 내장 데이터셋
- load_iris: 붖꽃 품종 분류를 위한 데이터 셋
- load_boston: 보스턴 주택 가격 예측을 위한 데이터 셋 $($ 주의: 이 데이터셋은 최신 버전 사이킷런에서는 제공되지 않음$)$
- load_wine: 와인 종류 분류를 위한 데이터셋
- load_breast_cancer : 유방암 여부 분류를 위한 데이터 셋
# 데이터 셋 로드 방법 : from sklearn.datasets import "데이터 셋 이름"
from sklearn.datasets import load_iris, load_wine
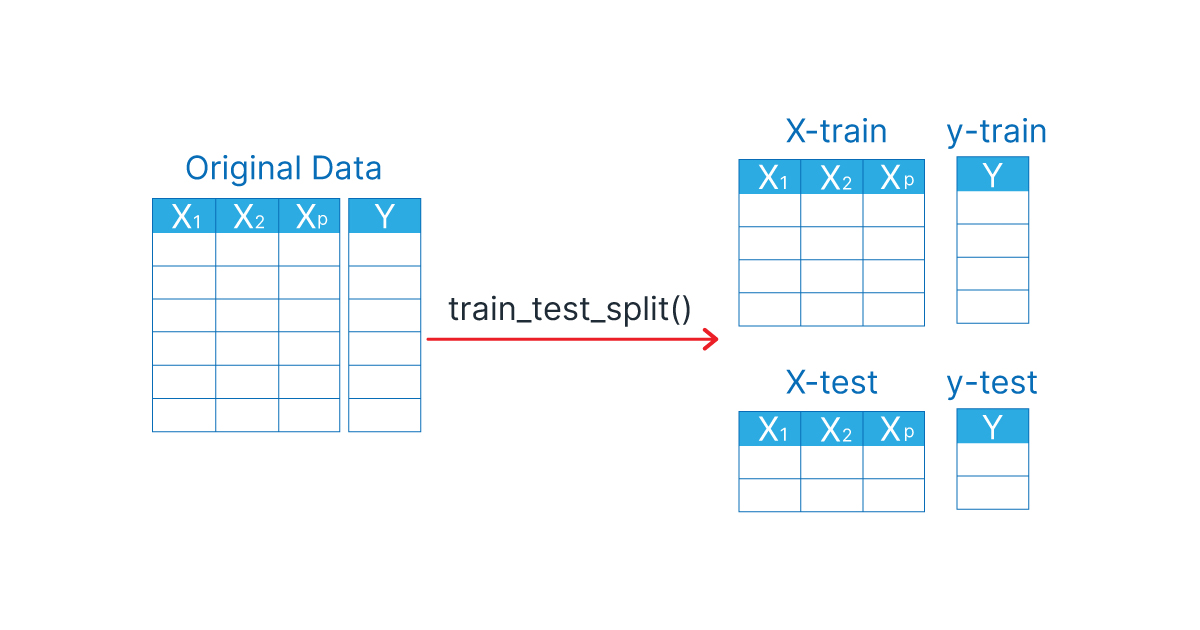
훈련 데이터 셋과 테스트 데이터 셋 분리
머신러닝 알고리즘을 학습시키기 위해서는 전체 데이터 셋을 train set과 test set로 분리하는 작업이 필요하다. 모델은 train set으로 학습을 한 후, 학습된 결과를 기반으로 test set의 데이터로 예측을 수행한다.
시험을 치르는 상황에 비유하자면, train set으로 학습하는 과정은 시험을 보기 전에 문제집을 풀면서 공부하는 과정이라고 생각할 수 있다. 그리고 문제집을 풀며 공부한 내용을 바탕으로 시험을 치르는데, 이 과정이 test set을 통해 정답을 예측하는 과정이라고 볼 수 있다.
사용법 예시:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42, test_size = 0.2, shuffle = True
- X_train: Train set 중 피처$($Feature$)$에 해당하는 부분
- X_test: Test set 중 피처$($Feature$)$에 해당하는 부분
- y_train: Train set 중 피처$($Target$)$에 해당하는 부분
- y_test: Test set 중 피처$($Target$)$에 해당하는 부분
train_test_split 메서드는 일반적으로 4~5개의 하이퍼파라미터 인자를 받는다.
| 하이퍼 파라미터 이름 | 역할 및 가질 수 있는 값 |
| *arrays | 분할하고자 하는 데이터를 나타냄. 보통 특성 데이터(X)와 타겟 데이터(y)가 전달 |
| random_state | 데이터를 분할하기 전에 데이터를 섞을 때 사용되는 난수 시드로, 이 값을 지정하면 여러 번 실행하더라고 같은 결과를 반복적으로 재현할 수 있다. |
| test_size | test set에 해당하는 데이터의 비율을 설정 $($ Default = 0.25 $)$ |
| shuffle | 분할하기 전 데이터를 섞을 지 말지 결정 $($ Default = True $)$ |
| stratify | 이 매개변수에 타겟 변수(y)를 전달하면, 훈련 세트와 테스트 세트가 전체 데이터셋의 타겟 변수의 클래스 비율을 유지하도록 분할 $($ Default = None $)$ |
사이킷런 라이브러리에 관해서는 세 파트로 나누어 올릴 예정이다.
- Part 2: 인코딩, 정규화
- Part 3: 교차검증, 하이퍼파라미터 최적화
참고 문헌
파이썬 머신러닝 완벽 가이드 - 예스24" target="_blank" title="파이썬 머신러닝 완벽 가이드" rel="noopener" data-mce-href="http://파이썬 머신러닝 완벽 가이드 - 예스24">http://파이썬 머신러닝 완벽 가이드 - 예스24
파이썬 머신러닝 완벽 가이드 - 예스24
자세한 이론 설명과 파이썬 실습을 통해 머신러닝을 완벽하게 배울 수 있다!『파이썬 머신러닝 완벽 가이드』는 이론 위주의 머신러닝 책에서 탈피해, 다양한 실전 예제를 직접 구현해 보면서
www.yes24.com
'산업공학 > Machine Learning' 카테고리의 다른 글
| [머신러닝] 앙상블 (Ensemble) (1) | 2024.04.29 |
|---|---|
| [머신러닝] 분류 (Classification) (2) | 2024.03.25 |
| [머신러닝] 평가지표(Evaluation) (7) | 2024.03.14 |
| [머신러닝] 사이킷런(Scikit - Learn) 라이브러리 part 2 : 데이터 전처리, 교차검증 (1) | 2024.03.04 |
| [머신러닝] 머신러닝(Machine Learning)이란? (2) | 2024.02.08 |