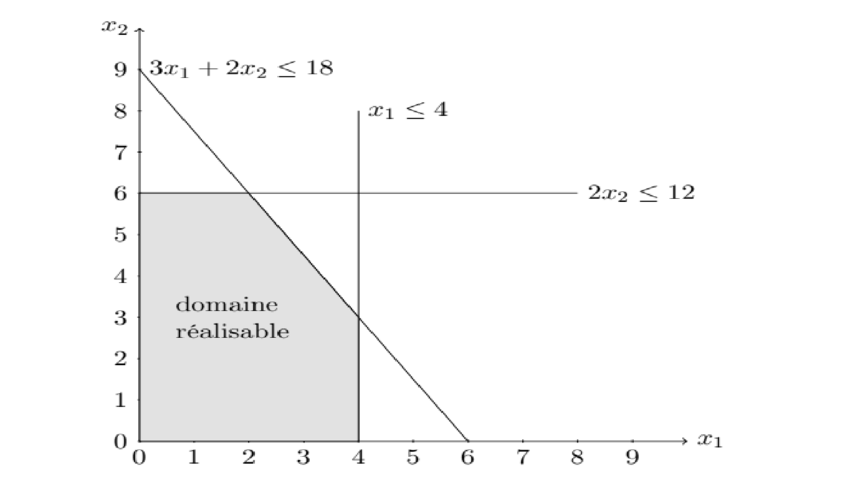
지난 주에 심플렉스 테이블의 행렬형 구조를 다루면서 초기테이블에 따라 특정 단계의 테이블 (혹은 최종 테이블)이 어떻게 구성되고, 변화하는지에 대해 살펴보았다. 그리고 '최적해 사후 분석' 포스팅에서 목적함수나 제약식의 변화에 따라 최적해가 변하는 민감도 분석에 대해서 살짝 다뤘었다. 오늘 포스팅에서는 심플렉스 테이블을 활용한 민감도 분석의 확장형 모델에 대해서 학습해보도록 하겠다. 심플렉스 테이블의 행렬형 구조" target="_blank" rel="noopener" data-mce-href="http://심플렉스 테이블의 행렬형 구조">http://심플렉스 테이블의 행렬형 구조 [경영과학] 심플렉스 테이블의 행렬형 구조지금까지 심플렉스 방법을 소개하면서 대수적 형태와 표의 형태로 설명하였다. 심플렉스..