이전 글에서 강화학습의 정의와 요소들에 대해 다뤄보았다. 강화학습이란 주어진 Environment 내에서 Agent가 Reward를 최대화하기 위한 목적으로 현재 State에서 다음 State로의 Action을 취하는 학습 과정을 의미한다. 이 학습 과정에서 Agent는 특정한 확률로 이전에서 다음 State로의 Action을 취하는 의사결정을 하게 되는데, 오늘은 이러한 의사결정을 하는 데에 기반이 되는 수학적 모델인 Markov Decision Process(MDP)에 대해 알아볼 것이다.
Grid World
MDP에 대해 알아보기 전에 우선 Grid World가 무엇인지 살펴보자.
Grid World란 강화학습이나 인공 지능 분야에서 사용되는 가상 시뮬레이션 환경이다. 이 환경은 격자(grid)로 이루어진 세계에서 에이전트가 주어진 목표를 효율적으로 달성하기 위해 최적의 경로를 찾아내는 방법을 학습하는 데 사용된다.
다음과 같이 4 x 3 크기의 그리드 월드를 가정해보자.

- State: S = {(1,1), (1,2), (1,3), ......, (4,3)}
- Action: A = {North, South, West, East}
- Rewards: End rewards (+1,-1) and small negative rewards(c) for every action.
- Noisy Movement: Agents do not always go as directed
-Action 'North' is taken: 80% 'North', and 10% each for 'West' and 'East' - If the next state is wall(2,2): The agent stays
Episode: (1,1) → (1,2) → (1,2) → (1,3) → (2,3) → (3,3) → (4,3)
Reward R = (5 actions) × c + 1(End Reward) = 5c+1
강화학습의 목표는 이 R을 최대화시키도록 Action을 선택하는 것이다.
Grid World에서의 Action:
1. Deterministic Grid World: 의도한 방향대로 100% 이동함
2. Stochastic Grid World: 의도한 방향대로 100% 이동하지 않고 랜덤으로 이동함.
강화학습에서는 대부분의 환경이 Stochastic Grid World의 특징을 갖는다.
Markov Property
Stochastic 또는 Random Process는 시점(time set)에 따라 인덱싱된 랜덤변수들의 집합이다.
- Discrete(이산형) State: S = {S0,S1,...,St−1,St,St+1,...}
- Continuous(연속형) State: S={St|t>0}
이 때, St는 Markov Property를 따른다면 Markov Process이다.
Markov Property란 Memoryless Property라고도 불리며, 이는 현재 State 인 St가 주어졌을 때, 미래 State인 St+1은 과거 State과는 전혀 무관하다는 뜻이기도 하다. 즉, 다음과 같이 표현 가능하다.
P(St+1=s′|St=s)=P(St+1=s′|S0=s0,S1=s1,...,St=s)
$P(S_{t+1} = s'|S_{t} = s)는s에서s'$으로의 State Transition Probability(상태변환확률)이라고 한다.
Markov 모델은 tuple(S,P) 형태이다.
- S: (유한한) State들의 집합 cf. 경우에 따라 무한할 수도?
- P: 상태변환확률 Matrix [Pij]
- Pij=Psisj=p(sj|si)=P(St+1=sj|St=si), ∑js.j=1(∀i)
[Pij]=[0.30.40.30.30.00.70.80.00.2]
환경이 Markov Property를 따르는 상황에서는 조건부 확률 식 P(A|B)에서 A가 St+1이고, B가 St임이 확실하므로 Psisj 혹은 p(sj|si) 의 표기를 주로 사용한다
Markov Decision Process (마르코프 의사결정 과정)
MDP는 모든 State이 Markov Process를 따르는 tuple(S,A,P,R,γ)이다.
- S: State Space(상태 공간)
- A: Action Space(행동 공간)
- P: s에서 s′으로의 State Transition Probability (상태변환 확률)은 Action a가 주어졌을 때, Pass′=p(s′|s,a)=P(St+1=s′|St=s,At=a)
- R: Reward Function(보상 함수) Rass′
- γ : Discount Factor(할인 계수), γ∈[0,1]
Transition Probability의 제시 여부에 따라 Model-based 와 Model-Free로 나뉜다.
| Model -Based | Model-Free | |
| 문제 해결 방식 | 모델을 기반으로 해결 | Sample Data를 기반으로 해결 |
| 학습 기법 | Dynamic Programming | Reinforcement Learning |
이제 다시 아까의 그리드 월드의 예시를 살펴보자
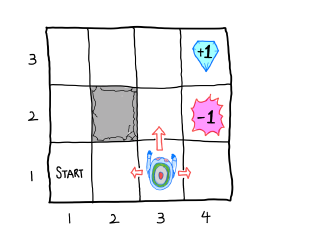
1. State set : S={(1,1),(1,2),(1,3),...,(4,2),(4,3)}
2. Action set : A = {North, South, East, West}
3. State transition probability:
- PNorth(3,1)(3,2)=0.8,PNorth(3,1)(2,1)=0.1,PNorth(3,1)(4,1)=0.1 etc.
4. Reward:
- REast(3,3)(4,3)=+1,REast(3,2)(4,2)=−1 etc.
- Rass′=c(c<0,c≠−1)
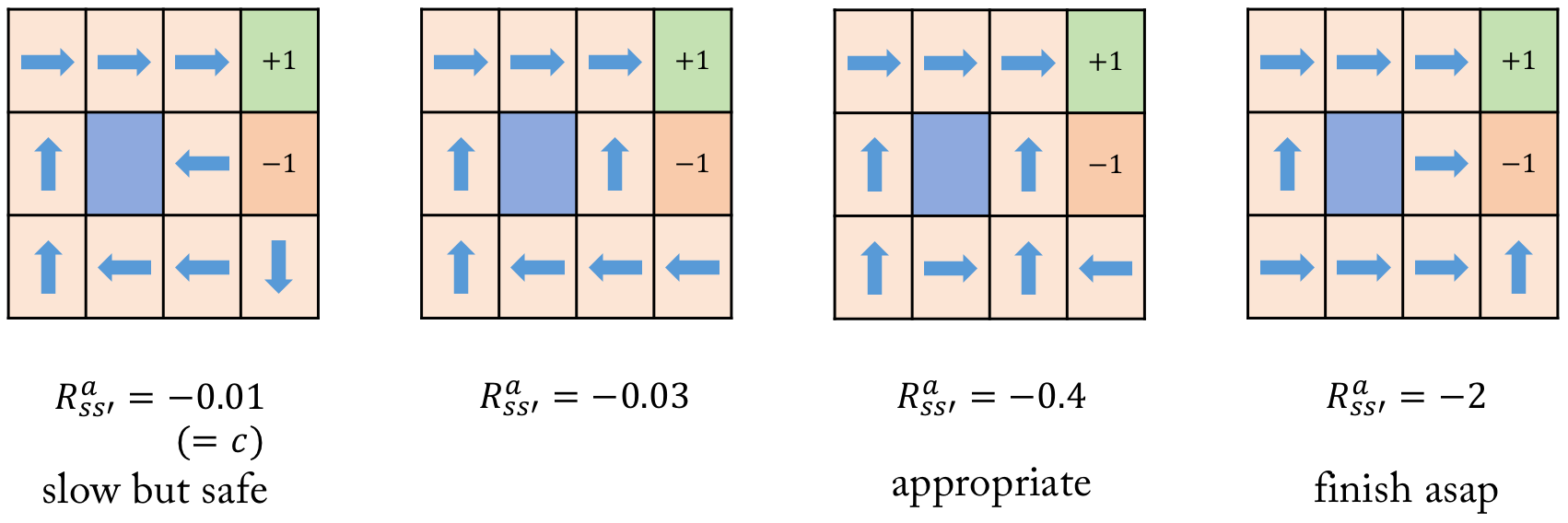
Optimal Policy in Grid World
MDP에서 우리는 최적의 Policy π∗:S→A를 찾는 것을 목표로 한다.
참고 문헌
오승상 강화학습 " target="_blank" title="오승상 강화학습" rel="noopener" data-mce-href="http:// 오승상 강화학습 ">http:// 오승상 강화학습
오승상 강화학습 Deep Reinforcement Learning
고려대학교 오승상 교수의 강화학습 Deep Reinforcement Learning 강의 입니다. (자료) https://sites.google.com/view/seungsangoh
www.youtube.com
'산업공학 > Reinforcement Learning' 카테고리의 다른 글
| [강화학습] Dynamic Programming (동적 계획법) (0) | 2025.03.31 |
|---|---|
| [강화학습] 4. Bellman Equation (1) | 2024.03.20 |
| [강화학습] 3. Reward and Policy (0) | 2024.03.20 |
| [코드 리뷰] RL4CO : PDP (Pickup and Delivery Problem) (1) | 2024.03.19 |
| [강화학습] 1. Introduction to Reinforcement Learning (0) | 2024.02.06 |