1. ML as an Optimization Problem
기계학습이 해야 할 일을 식으로 정의하면, 주어진 cost function $J(\theta)$에 대해, $J(\theta)$를 최소로 하는 $\hat{\theta}$를 찾는 것.
$$ \hat{\theta} = argmin_{\theta}J(\theta)$$
2. Iterative Optimization
2.1 General Prinicples
- Training Dataset $D$
- Model & Predicted Output: $\hat{y} = h_{\theta}(x)$
- Cost Function : $J(\theta)$
1) 파라미터 $\theta$ 초기화
2) 모든 epoch에 대해
- 출력값 $\hat{y}$ 예측, cost $J(\theta)$ 계산하기
- 만약 $J(\theta)$가 최적이라면, 학습 종료
- 최적이 아니라면, 파라미터 $\theta$ 업데이트, 1번 반복

2.2 Parameter Update
1) $L(\theta)$가 작아지도록 $\Delta{\theta}$를 구한다.
2) $\theta$를 업데이트 : $\theta = \theta + \Delta{\theta}$
2.3 Learning Modes
- On-line mode: 모든 training sample에 대해 파라미터 업데이트
- Batch mode: 모든 training epoch에 대해 파라미터 업데이트
- Mini-Batch mode: 모든 훈련집합의 부분집합에 대해 파라미터 업데이트

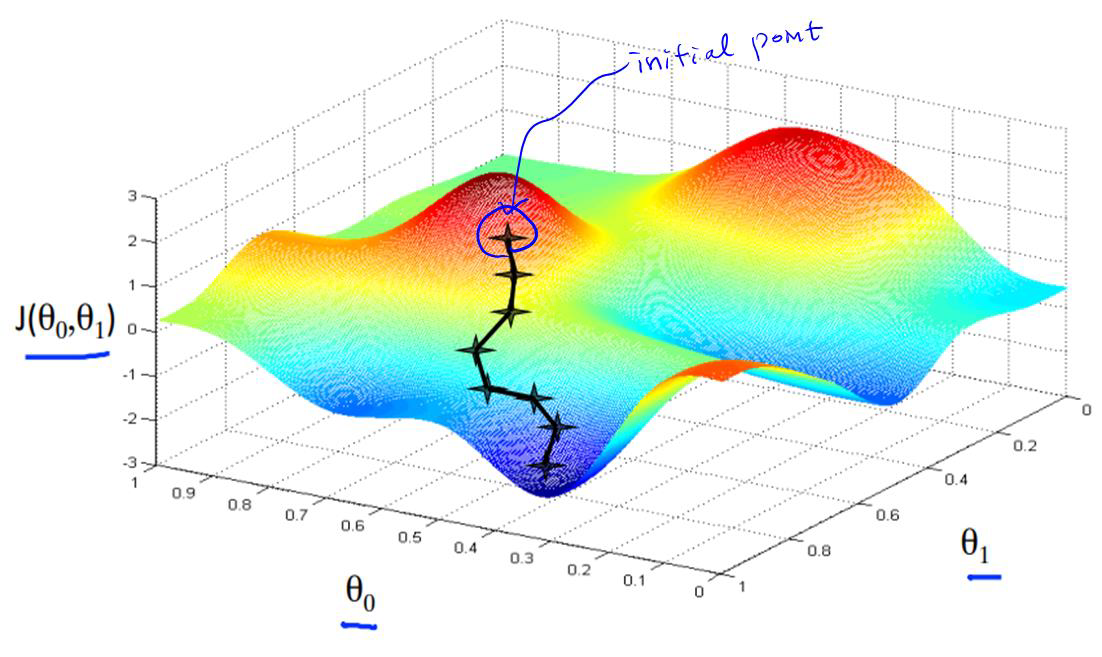
3. Gradient Descent
Gradient는 "기울기"이다. 경사하강법의 목적은 모델의 Weight $w$를 어떻게 바꿔야 Cost를 줄일 수 있을까?
$$Cost = J(\theta)$$
- Gradient $g \geq 0$인 경우 : $\Delta J \leq 0$ 이려면 $\theta$ 감소
- Gradient $g \leq 0$인 경우 : $\Delta J \leq 0$ 이려면 $\theta$ 증가
따라서 경사하강법은 경사 $\frac{dJ}{dw}$의 반대 방향으로 weight를 변화시키는 것

◈ Parameter Update
Cost Function의 Gradient에 기반하여: $${\color{Blue}{\theta = \theta - \alpha\frac{dJ}{d\theta}}}$$
- $\alpha$ : Learning Rate (학습률), 학습을 얼마나 빠르게 진행할 지를 결정해주는 값

◈ Batch Learning Modes

Gradient Descent는 매 훈련 샘플마다 파라미터의 업데이트를 수행하기 때문에 샘플들의 순서에 의존할 수 있다. 따라서 결과가 training example의 순서에 의존하지 않도록 example들의 순서를 임의로 선택해서 파라미터를 업데이트하는데, 이를 Stochastic Gradient Descent (SGD) 라고 한다.

4. GD vs. SGD

5. Minibatch Gradient Descent (Minibatch GD)
◈ Minibatch Learning Modes
- 모든 훈련집합의 부분집합에 대해 파라미터 업데이트
- Training set을 여러 개의 minibatch로 나누고, minibatch에 속한 모든 training example의 Gradient를 평균한 후 한꺼번에 갱신
- Online mode와 Batch mode의 중간으로 볼 수 있음
◈ Minibatch Learning Modes are most commonly used in ML & DL
- 부분집합 (subset)을 선택하면 Vectorization을 활용할 수 있다.
- 온라인"보다 업데이트 횟수가 적기 때문에 업데이트 시 노이즈가 적다.
- 배치"보다 더 많은 업데이트/에포크를 수행하므로 더 빠르게 수렴한다.
'산업공학 > Deep Learning' 카테고리의 다른 글
| [딥러닝] PyTorch - Transforms (1) | 2024.08.17 |
|---|---|
| [딥러닝] PyTorch - Dataset and Data Loader (0) | 2024.08.17 |
| [딥러닝] PyTorch - Tensor (0) | 2024.08.16 |
| [딥러닝] DL 실무 기초 개념 (0) | 2024.08.16 |
| [딥러닝] Neural Network (1) | 2024.07.15 |