시계열 분석을 이용한 주가 예측 프로젝트
본 프로젝트는 BITAmin 이라는 빅데이터 연합 동아리에서 진행한 프로젝트로, 시계열 분석이라는 대주제 내에서 토픽으로 선정한 팀 프로젝트이다.
기간: 2024.01 ~ 2024.02
주제: 뉴스 기사와 감성 분석을 통한 주가 예측
목적: 선정 주식과 관련된 뉴스 기사를 감성 분석한 데이터와 주식의 기술적지표 데이터를 분석하여 미래 종가 예측
1. Introduction
1.1. Background of Topic Selection
- 뉴스가 주가 변동에 미치는 영향 탐구
- 주가 예측에 뉴스를 활용할 수 있는지 탐구
- 주가를 예측하는 데 사용하는 데이터로 뉴스의 감성분석 및 토픽 모델링 결과 사용
- 뉴스 기사는 주로 한 기업에 대해 보도하고 있어서 예측 대상은 한 개의 주식 종목으로 정함
- 뉴스 감성 분석/토픽 모델링 결과를 활용하여 주가를 예측하는 프로젝트는 많지 않아, 직접 뉴스 데이터를 활용
- 장기적인 추세를 고려할 수 있는 주가 예측 모델 구현
- 기존의 주가 에측 프로젝트는 주로 모델의 예측 일수나 시퀀스 길이를 1~5로 선정
- 짧은 시간 동안의 주가 변동을 예측한 프로젝트와 달리 예측 일수와 시퀀스 길이를 늘려 단기적인 변동뿐만 아니라 장기적인 추세를 고려한 예측 결과 얻고자 함
- 기존 프로젝트에서 주가 에측 그래프가 실제 주가 그래프를 단순 평행이동한 형태로 나타나는 문제 해결
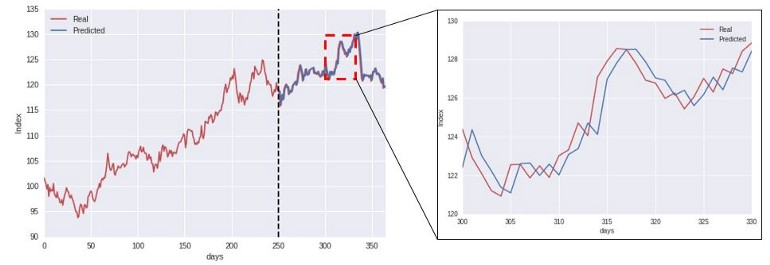
1.2. Brief Project Introduction
- [목표]: 뉴스 데이터를 활용한 주가 예측 모델의 최적화 및 효율적인 파라미터 선정
- [주요 내용]:
- 장기적인 추세 예측에 효과적인 모델 판별: LSTM vs. GRU vs. Transformer
- 실험을 통한 모델 파라미터 튜닝
- 뉴스 감성분석과 토픽 모델링의 주가 예측 유용성 검토
- 각 실험 결과 평가에 필요한 지표 선정
- [개발 환경]: Colab
- [개발 언어]: Python, Pytorch, Selenium
1.3. Data Collection
- 주가 데이터
- FinanceDataReader 라이브러리를 활용하여 NETFLIX 기업의 2018.01.02 ~ 2023.12.29 주가 데이터 수집
- 동일한 기간에 대한 핀터레스트, 메타플렛폼스, 스포티파이의 주가 데이터 수집
- 뉴스 데이터
- Stock News API를 활용하여 2018.01.02 ~ 2023.12.29 기간 동안 발행된 NETFLIX 기업과 관련된 뉴스 데이터 수집


tickers_only = 'NFLX' #netflix stock
items = 60
pages = 1
key = API_KEY
sortby = 'rank'
dates = ['01012018-06312018', ..... , '12022023-12312023']
url = f'https://stocknewsapi.com/api/v1'
famous_sources = [
'Bloomberg+Markets+and+Finance',
'Bloomberg+Technology',
'Business+Wire',
'CNBC','CNBC+International+TV','CNBC+Television',
'CNN','CNN+Business',
'ETF+Trends','Fast+Company',
'Yahoo+Finance','Wall+Street+Journel',
'NYTimes','The+Guardian','Fox+Business',
'Forbes','New+York+Post','Business+Insider','Reuters'
]
for date in dates:
req_params = {
'tickers-only': tickers_only,
'sortby': sortby,
'date': date,
'items': items,
'page': pages,
'extra-fields':'id, rankscore',
'token': key
}
res_json = json.loads(res_0213.content)['data']
if len(res_json)==0:
continue
res_df = pd.DataFrame(data=res_json).drop(columns=['image_url','tickers'])
# 날짜 형식 맞추기
res_df['date'] = pd.to_datetime(res_df['date'],format='%a, %d %b %Y %H:%M:%S %z')
news_df = pd.concat([news_df,res_df],axis=0)
res = requests.get(url = url, params = req_params)
이 코드는 주어진 날짜 범위(dates 리스트에 있는 각 범위)에 대해 Netflix(NFLX) 주식과 관련된 뉴스 항목을 가져오기 위한 것으로, Python의 requests 라이브러리를 사용하여 stocknewsapi.com의 API에 요청을 보낸다. 각 요청은 req_params 내의 매개변수를 포함한다.
2. Data Preprocessing
2.1. Make Derived Variable
- RoC(Range of Change) : 변화율: 1D_RoC(1일 변화율), 5D_RoC(5일 변화율)
- MA(Moving Average) : 이동평균: 5MA(5일 이동평균), 120MA(120일 이동평균)

이전 시점을 포함하여 rolling하는 변수이므로 생성된 파생변수의 첫 시점은 NaN 상태, 따라서 우리가 학습에 사용할 데이터는 2019년도 이후부터지만, 2018년 데이터를 추가로 수집해 파생변수 생성에 활용
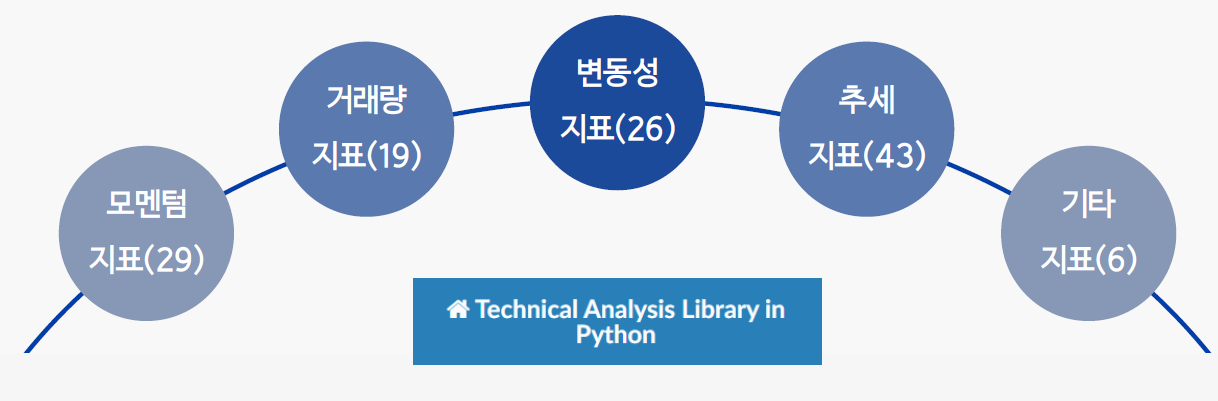
2.2. Add Indecators
TA(Technical Analysis) Library
- 금융 시계열 데이터 셋(시가, 마감, 고가, 저가, 거래량)에 대한 기술 분석 라이브러리
View TA" target="_blank" rel="noopener" data-mce-href="http://View TA">http://View TA
Documentation — Technical Analysis Library in Python 0.1.4 documentation
Rate of Change (ROC) The Rate-of-Change (ROC) indicator, which is also referred to as simply Momentum, is a pure momentum oscillator that measures the percent change in price from one period to the next. The ROC calculation compares the current price with
technical-analysis-library-in-python.readthedocs.io
한국투자증권 mts에서 지원하는 37개 지표를 선정하였다.
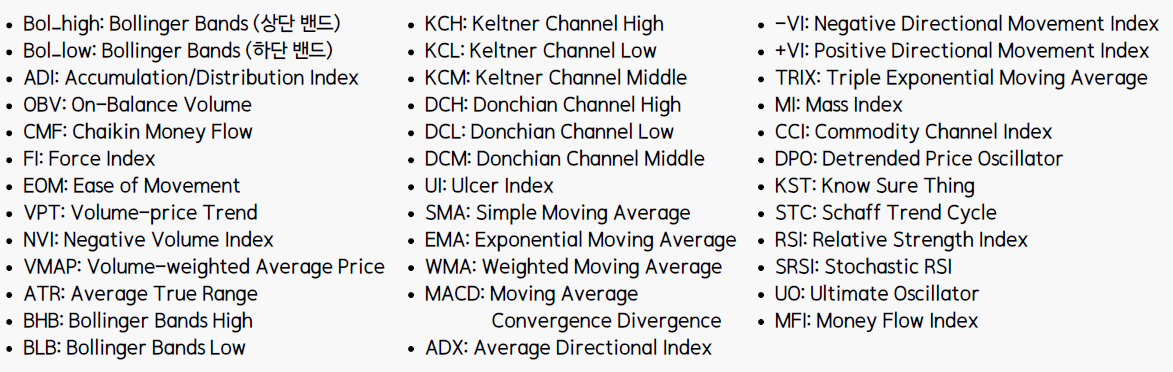
2.3. Peer Analysis : Add similar stock price
PINS(핀터레스트), FB(메타플렛폼스), SPOT(스포티파이)
Netflix와 유사한 사업을 영위하는 기업의 해당 기간 종가를 feature로 추가
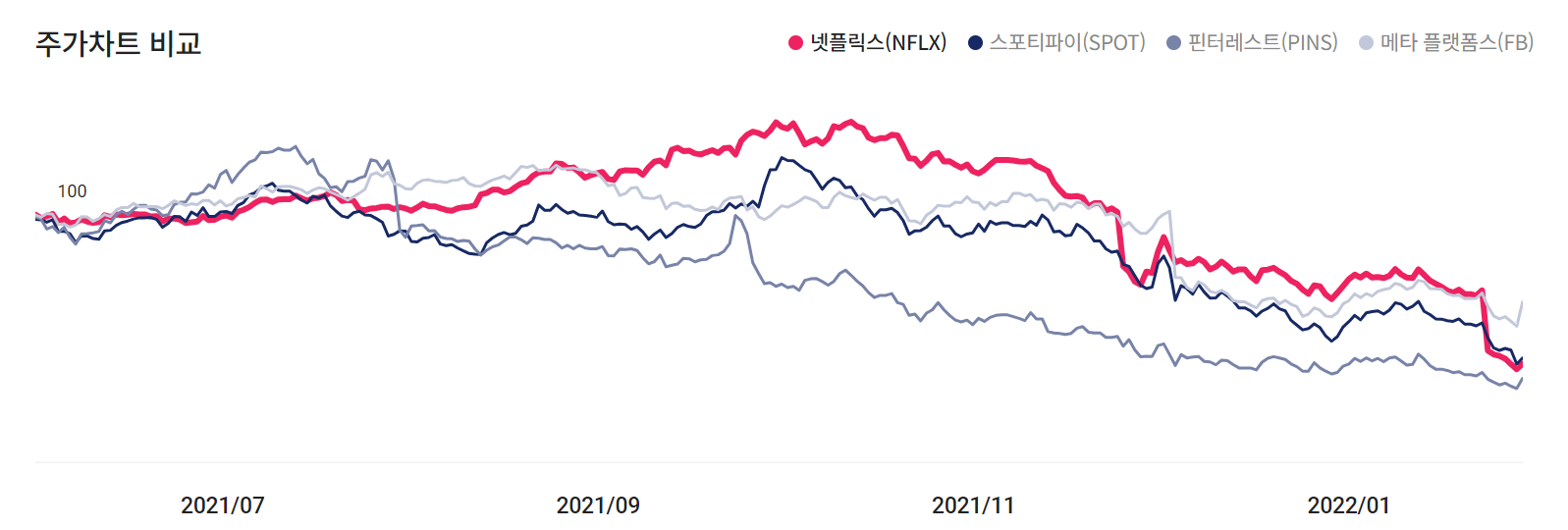
PINS의 경우 2019년 4월 22일에 최초 상장되었으므로 상장 이전의 결측치는 최초 상장일의 종가로 대체
2.4. Remove Multicollinearity
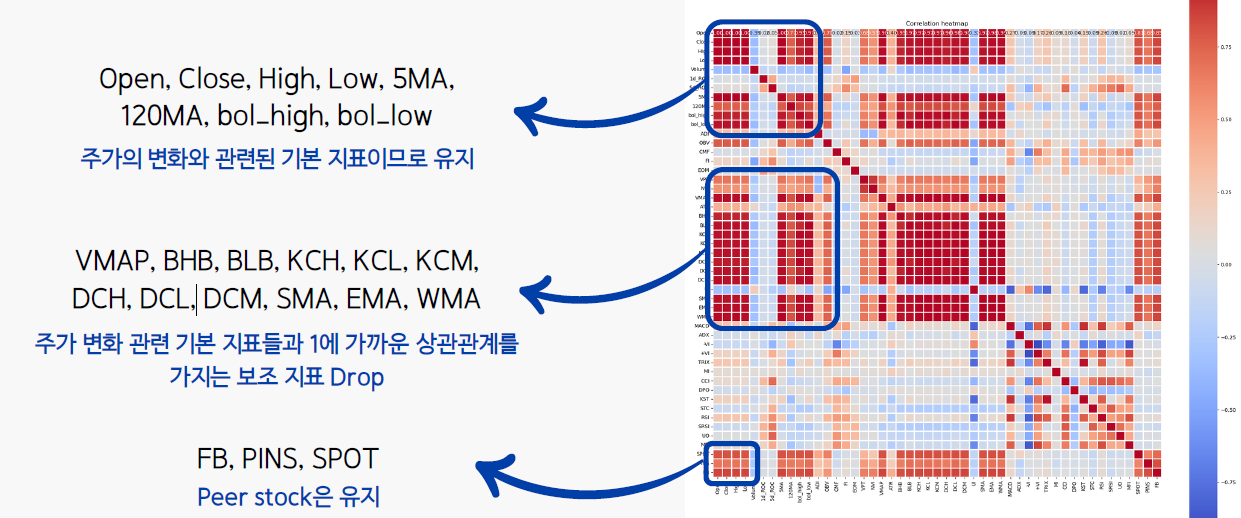
2.5. Make Derived Variable for New Topic & Sentiment
- Topics → Label Encoding → 5MM, 60MM, 120MM
- Sentiments → OneHotEncoding → 5MA, 60MA, 120MA, 5MM, 60MM, 120MM
당일 뉴스가 당일 주가에 영향을 미칠 가능성은 적기 떄문에 과거 뉴스의 영향력을 측정하기 위해 Moving Average(MA), Moving Mode(MM) 추가
2.6. Final Dataset:
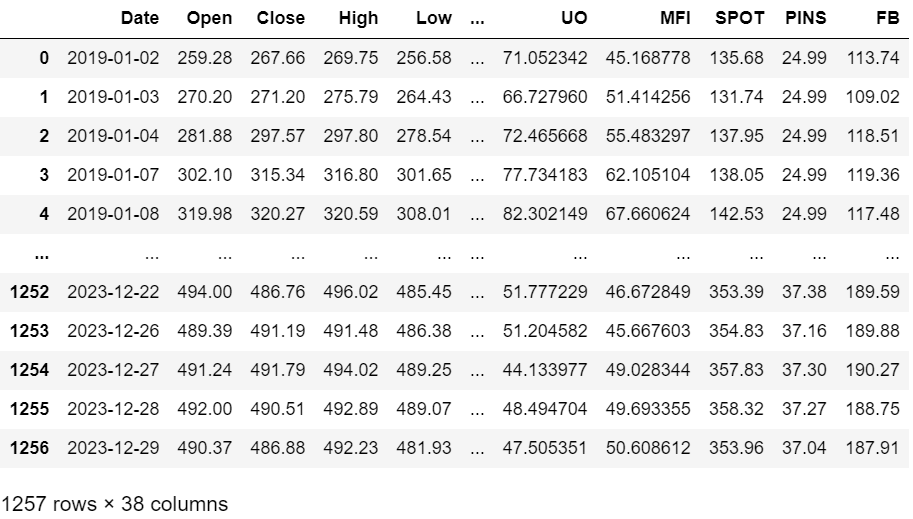
★ Dataset 1: stockOnly_df (1257 x 38)
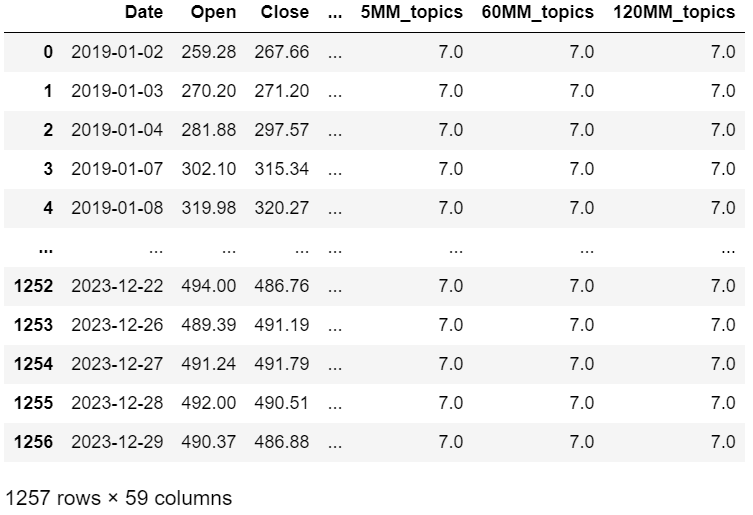
★ Dataset 2: total_df (1259 x 59)
3. Modeling
3.1. Time Series
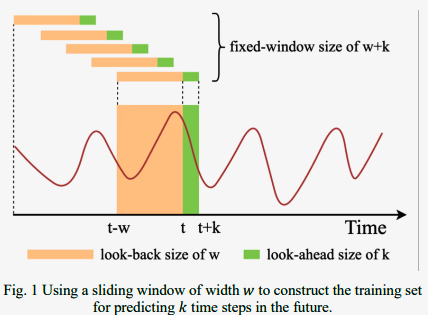
시계열 분석은 시간에 따른 데이터 패턴을 분석하여 미래 값을 예측하는 분석이다.
- Sequence Length $(w)$: 한 번에 모델에 입력되는 연속된 데이터 수 (input)
- Predict Size $(k)$ : 모델이 예측할 미래 데이터 길이 (output)
→ 고정된 Window Size: $w + k$
3.2. Modeling
(1) Step 1: Sequence Length = 60, Predict Size = 10 → 학습에 사용할 1개의 시퀀스 데이터 형태
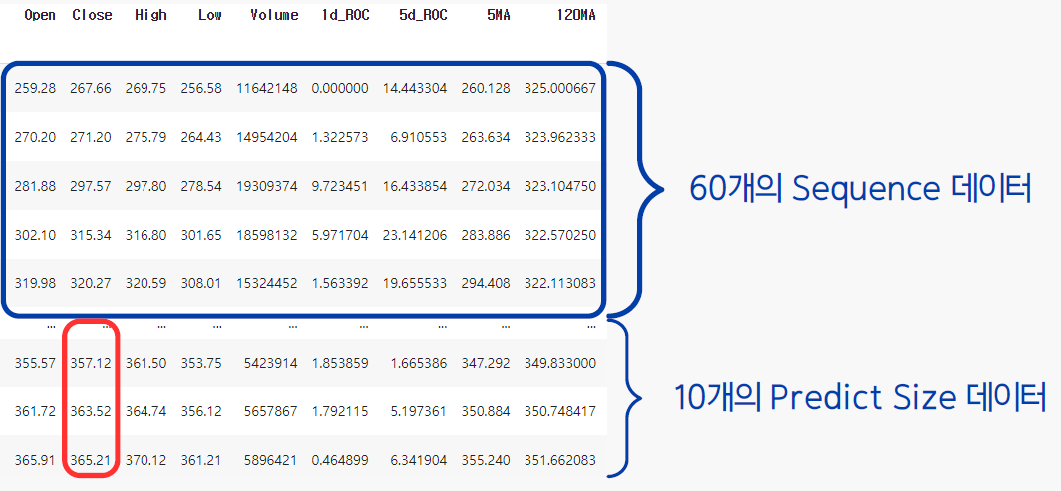
(2) Step 2: Define Model
- LSTM: 기존의 주가 예측 모델이 주로 LSTM을 사용했지만, 주로 sequence length = 1, prediction size = 1로 예측을 하기 때문에, 파라미터들을 다양하게 조정해서 예측해보는 것이 유의미할 거라 판단
- GRU: 기존의 LSTM 모델의 복잡성을 간단화함으로써 문제점을 극복
- Transformer: NLP에서 좋은 성능을 보이는데, 주가 예측에도 유의미한 결과를 가져오는 지 확인하기 위해 선택
(3) Step 3: Model Comparison
- Comparison 1: 무엇을 Target으로 할 것인가? 'Close' vs. '1D_RoC'
- Comparison 2: 뉴스를 포함 여부 성능 비교 'News + Stock' vs. 'Only Stock'
- Comparison 3: 어떤 모델이 가장 예측을 잘 하는가? 'LSTM' vs. 'GRU' vs. 'Transformer'
4. Conclusion and Limitation
4.1. Evaluation
예측 평가 기준: 시계열 모델의 손실함수로 MSE는 너무 커서 RMSE 선택
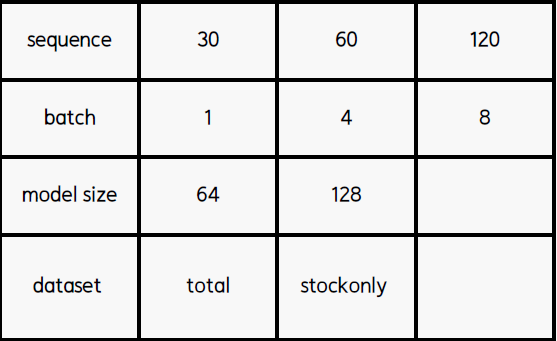
Key Point: 다음과 같이 Case를 나누어 따져서 각 Case별로 아래 표의 파라미터를 조정하며 분석
- 어떤 변수를 Target으로 예측하는 것이 좋을까? (Comparison 1)
- 뉴스 데이터는 예측에 유의미한 영향을 주는가? (Comparison 2)
- 어떤 모델이 예측에 가장 효과적인가? (Comparison 3)
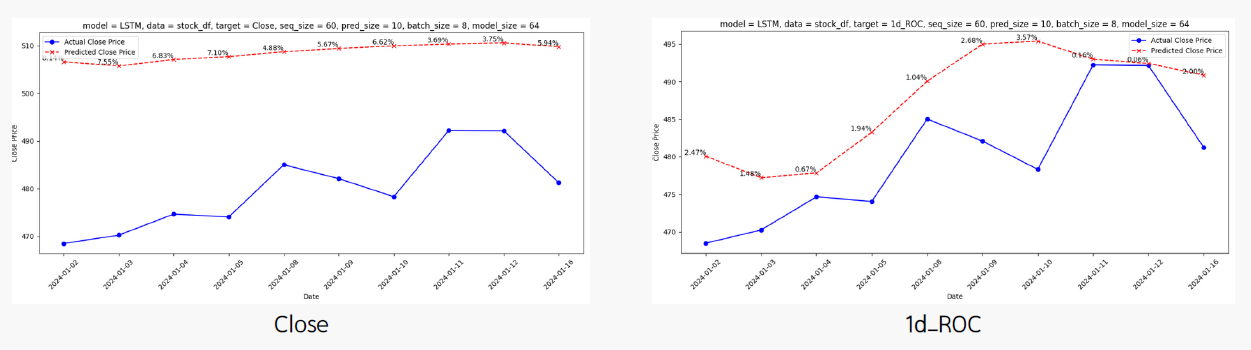
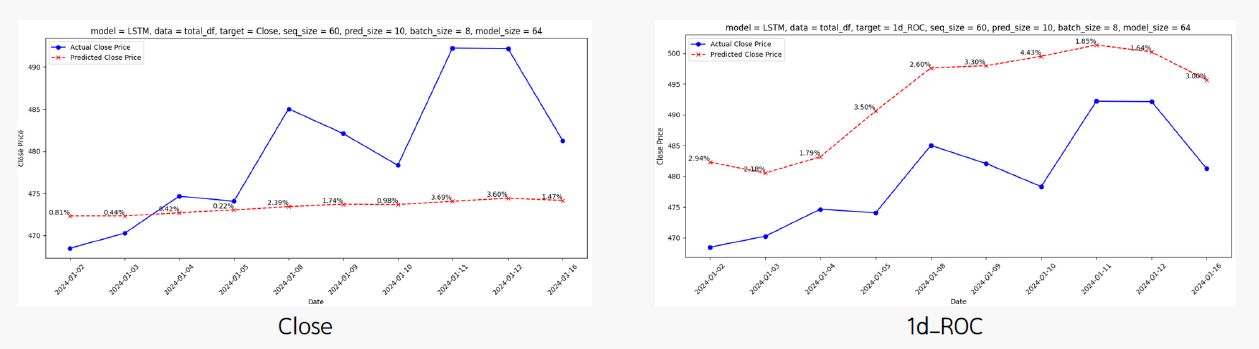
4.2. Target Selection: "Close vs. 1D_Roc"
- Dataset: stockOnly_df
- model: LSTM (seq = 60, batch = 8, model_size = 64)
- Dataset: total_df
- model: LSTM (seq = 60, batch = 8, model_size = 64)
4.3. Model Result
(1) LSTM
(2) GRU

(3) Transformer
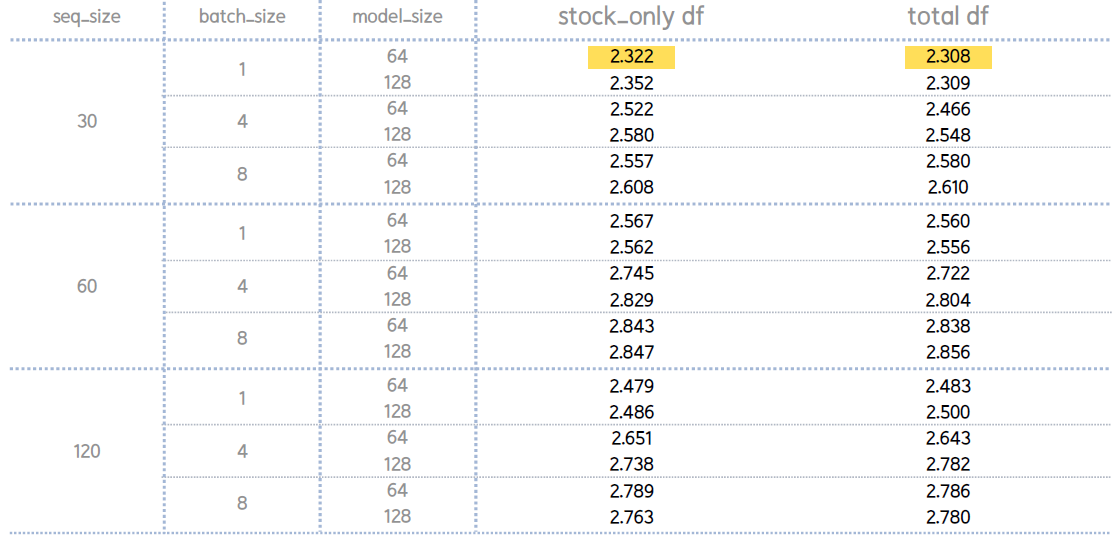
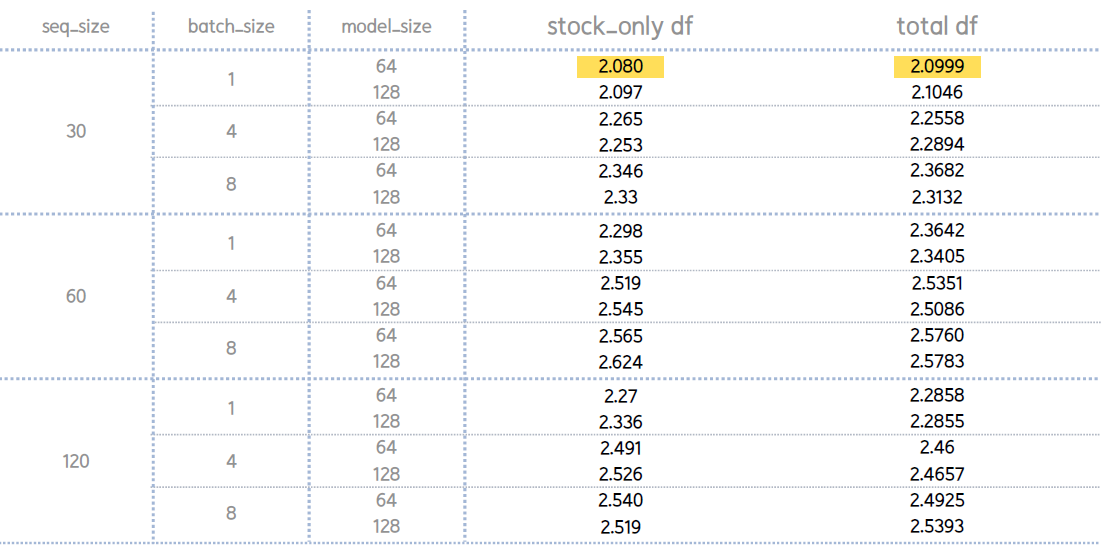
4.4. Compare Each Parameter

- 세 모델 중 LSTM의 loss 평균값이 가장 작고, Transformer 의 loss 평군값이 가장 큼
- GRU 모델에서는 주식 데이터로만 사용한 경우, LSTM과 Transformer에서는 뉴스데이터를 포함한 경우 loss 평균이 가장 작음.
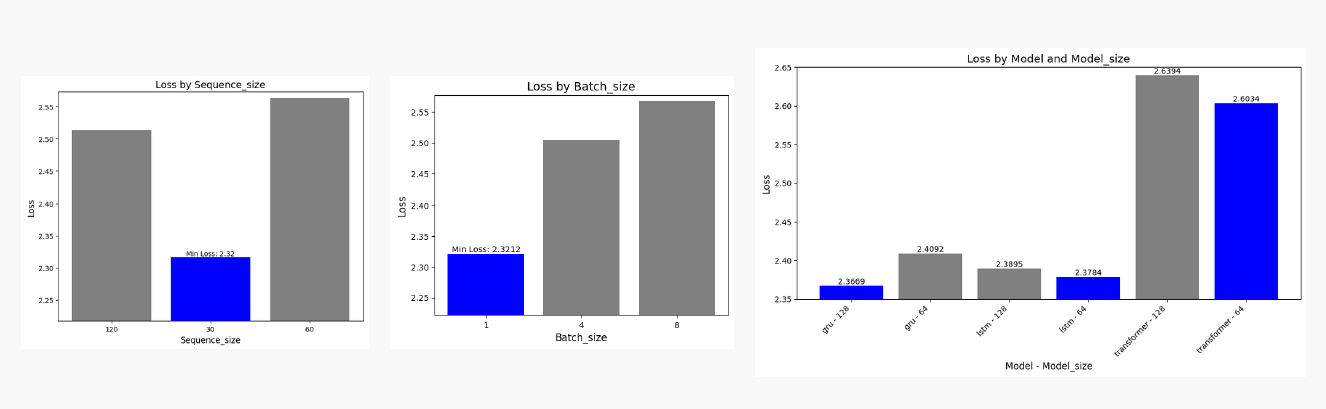
- loss 값은 sequence_size, batch_size는 값이 작을 수록 유의미한 결과
- model_size는 LSTM, Transformer는 64에서, GRU는 128에서 더 유의미한 결과
4.5. Best Parameter for Each Model
validation_loss를 기준으로 모델별로 최적의 파라미터 조합을 선정하여 50번 반복
→ 평균값으로 경향성과 오차율 파악 후 최종 모델 선정 (오차율을 사용한 이유는 주식은 수익률이라는 지표를 사용하는데, 오차율이 수익률과 유사한 지표라고 판단했기 때문)
def error_ratio(pred, true):
return np.mean(np.abs(pred-true)/true)
- [LSTM] stock_only, seq 30, batch1, model 64 평균 오차율 1.85%
- [GRU] total_df, seq 30, batch 1, model 128 평균 오차율 1.66%
- [Transformer] total df, seq 30, batch 1, model 64 평균 오차율 1.62%
◆ LSTM
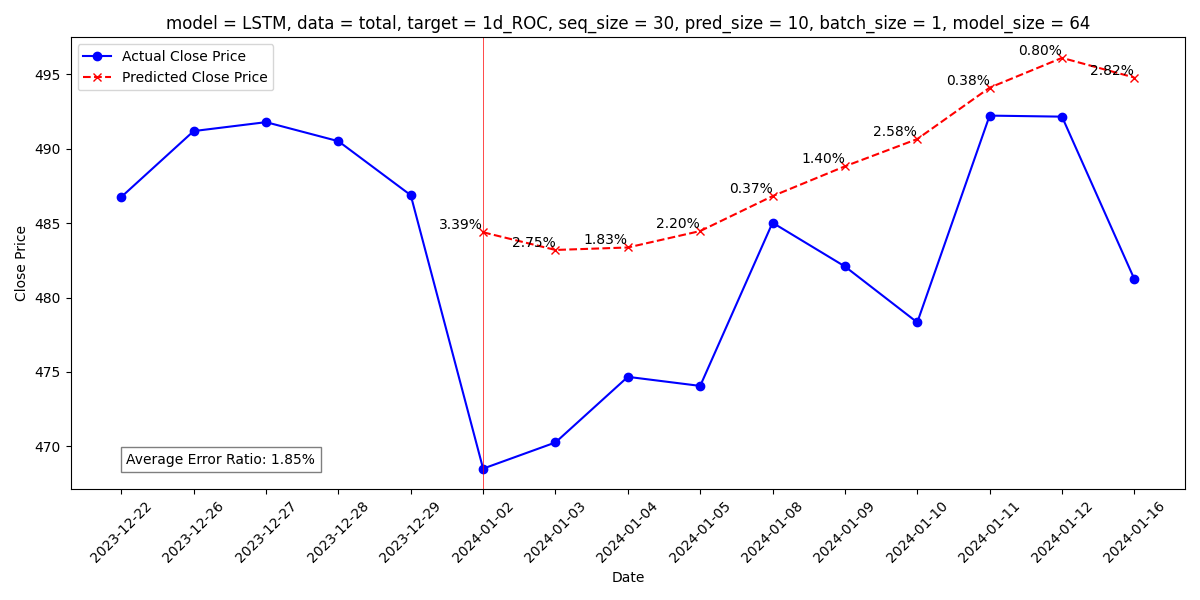
◆ GRU
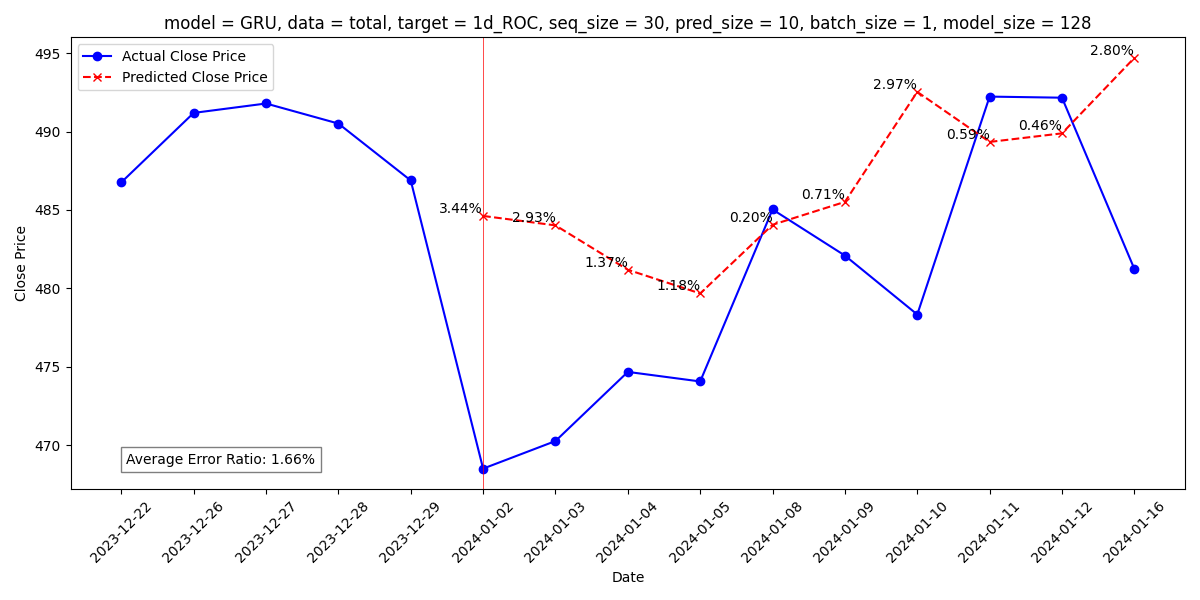
◆ Transformer
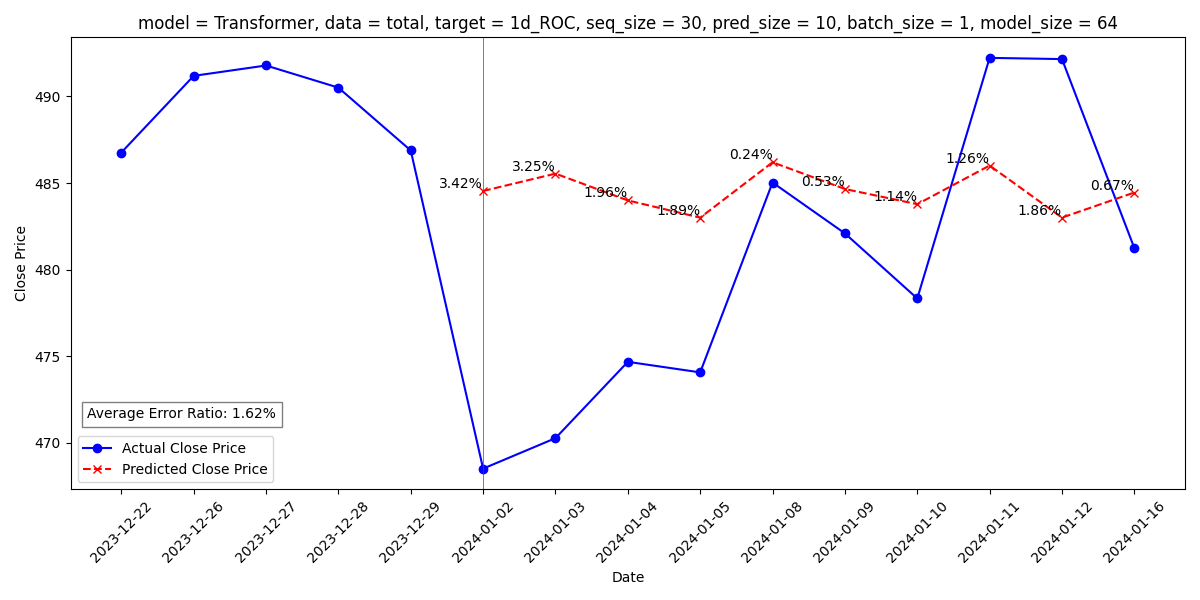
4.6. Limitations
- 금융시장에서는 예상치 못한 사건이 발생하는 일이 잦아 예측이 어려움
- 수치만으로는 모델의 성능을 평가하기 어려워 일일이 예측 그래프를 확인해야 함
- 뉴스 Topic NLP로 감성분석과 토픽모델링을 시도했지만, 시퀀스 길이 문제와 정확도를 높이는 것에 한계가 있어 API를 사용
- 일반적인 에측의 경우, 5%의 오차가 좋은 평가를 받을 수 있으나 주식 시장에서 5%는 큰 손실 또는 큰 이익
Codes" target="_blank" title="Codes" rel="noopener" data-mce-href="http://Codes">http://Codes
GitHub - taekyounglee1224/Bitamin: 빅데이터 연합동아리 Bitamin에서 진행한 실습 및 프로젝트
빅데이터 연합동아리 Bitamin에서 진행한 실습 및 프로젝트. Contribute to taekyounglee1224/Bitamin development by creating an account on GitHub.
github.com
위 링크 클릭 → DL Session → Projects → Stock Price Prediction with News Topic