시계열 예측과 강화학습을 활용한 시스템 트레이딩 수익 극대화
본 프로젝트는 BITAmin 이라는 빅데이터 연합 동아리에서 진행한 프로젝트로, 시계열 분석이라는 대주제 내에서 토픽으로 선정한 팀 프로젝트이다.
기간: 2024.03 ~ 2024.06
주제: 강화 학습을 이용한 시계열 예측 및 시스템 트레이딩으로 포트폴리오 최적화
목적: 시계열 예측으로 다음 5일 간의 각 종목의 수익률을 예측 (최대 변동률 기준) 후 상위 6개 선정, 선정된 6개 종목으로 강화학습을 이용한 단타 매매
1. Introduction
1.1. Problems of DL Time Series Forecasting
- 노이즈가 심하다
- 데이터 수가 부족하다
- 과적합이 심한 경우가 많다
1.2. Solutions
- Time Series Forecasting: 모든 종목에 대해 강화학습 예측을 할 수는 없기 때문에 다음 일주일간 가장 큰 종가 수익률을 보일 종목을 예측한다
- Reinforcement Learning: 분 단위 거래를 학습하여 단타매매를 실행한다 (하루 381개 데이터)
1.3. Environments
- conda virtual environment
- Python 3.7+
- PyTorch 1.13.1
conda install python==3.7
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
conda install pandas
conda install matplotlib
conda install -c conda-forge ta-lib
pip install -r trading_requirements.txt

2. Data Preprocessing (Time Series)
주가 데이터 수집은 Finance Data Reader를 통해 수집하였고 2017년 1월부터 한국 주식 시장 지수(KOSPI)의 종가 데이터를 수집하였다.
2.1. Log Transform
import numpy as np
import pandas as pd
df = pd.DataFrame(data)
df_log = df.apply(np.log)
데이터 정규화와 변동성 감소를 위해 원본 데이터를 Log Transform 하였다.
2.2. Factor 사용
RSI(상대 강도 지수)나 Sharpe Ratio(샤프 비율) 같은 팩터들을 주가 예측 모델에 추가로 사용하는 것은 예측 성능을 향상시키기 위해 유용하다. 이러한 팩터들은 주가의 움직임과 위험을 보다 잘 설명할 수 있는 정보들을 제공하기 때문에 모델의 예측력을 강화할 수 있다.
1) RSI (Relative Strength Index)
RSI는 주식이 과매수 상태인지 과매도 상태인지를 알려주는 지표로, 주가의 추세 강도를 파악할 수 있다. 이를 통해 주가의 추세의 전환점을 예측해서 진입과 진출 시점을 파악하는데 도움이 된다.
0에서 100사이 값(%)으로 표현되며, 30 이하면 과매도 상태로 곧 주가가 반등할 가능성이 높다고 판단하고, 70 이상이면 과매수 상태로, 곧 주가가 하락할 가능성이 높다고 판단한다.
RSI를 계산하는 식은 다음과 같다.
def RSICalculator(df, window_size=10): # window_size = 10
df_RSI = pd.DataFrame(columns=df.columns)
df_pct = df.pct_change().fillna(method='bfill').copy()
for col in df_RSI:
df_col = df_pct[[col]].copy()
df_col[col+'_상승폭'] = np.where(df_col[col] >= 0, df_col[col], 0)
df_col[col+'_하락폭'] = np.where(df_col[col] < 0, df_col[col].abs() , 0)
df_col[col+'_AU'] = df_col[col+'_상승폭'].ewm(alpha=1/window_size, min_periods = window_size).mean()
df_col[col+'_AD'] = df_col[col+'_하락폭'].ewm(alpha=1/window_size, min_periods = window_size).mean()
df_RSI[col] = df_col[col+'_AU'] / (df_col[col+'_AU'] + df_col[col+'_AD'])
return df_RSI.iloc[window_size:,:].reset_index(drop=True)
2) Sharpe Ratio
Sharpe Ratio는 투자 수익률의 위험 대비 효율성을 측정하는 지표로, 리스크를 효율적으로 관리하여 예측 모델이 더 신뢰성 있는 결과를 도출하도록 도와준다.
- : 위험 포트폴리오의 수익률
- : 무위험 자산의 수익률
- : 위험 포트폴리오의 리스크
def SharpeCaculator(df, window_size=10, risk_free_rate=0.035):
df_sharpe = pd.DataFrame(columns=df.columns)
df_pct = df.pct_change().fillna(method='bfill').copy()
days_10_risk = ( risk_free_rate / 10) * (10 / 365) # (10년 국채 금리 / 10년) * (365일중 10일)
for col in df_sharpe.columns:
df_col = df_pct[[col]].copy()
#10일간 수익률 평균
df_col[col+'10_Avg'] = df_col[col].rolling(window=10).mean()
df_col[col+'10_Avg'].fillna(df_col[col+'10_Avg'].mean(), inplace=True) #어차피 지울것이므로 임의 생성.
##10일간 수익률 표준편차
df_col[col+'10_vol'] = df_col[col].rolling(window=10).std()
##sharpe ratio 계산
df_sharpe[col] = (df_col[col+'10_Avg'] - days_10_risk) / df_col[col+'10_vol']
return df_sharpe.iloc[window_size:,:].reset_index(drop=True)
3. Model Selection
3.1. LSTM
- RNN 기반의 모델로, 장기 의존성 문제를 해결하여 오랫동안 데이터 반영 가능
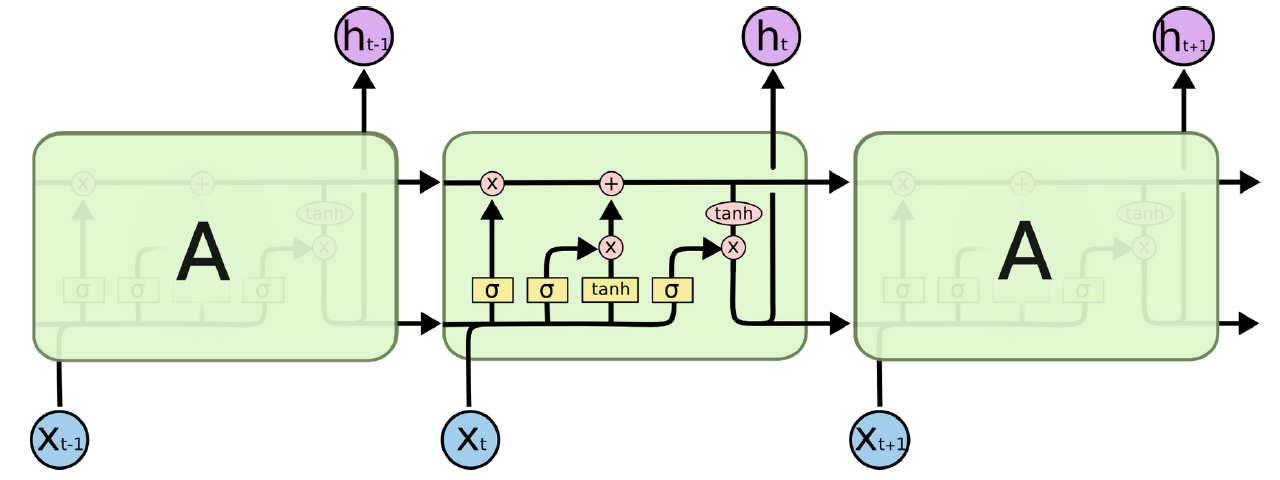
[평가 결과]
MAE : 3.7084
MSE : 15.0189
3.2. DLinear(LSTF-Linear)
- Transformer 구조 + 선형 예측
기존 트랜스포머에서 self attention문제로 발생하는 정보손실을 방지하기 위해 탄생한 모델로, 데이터를 추세와 계절성으로 분해하여 1-layer linear Network에 통과시켜 예측 결과를 얻는 구조
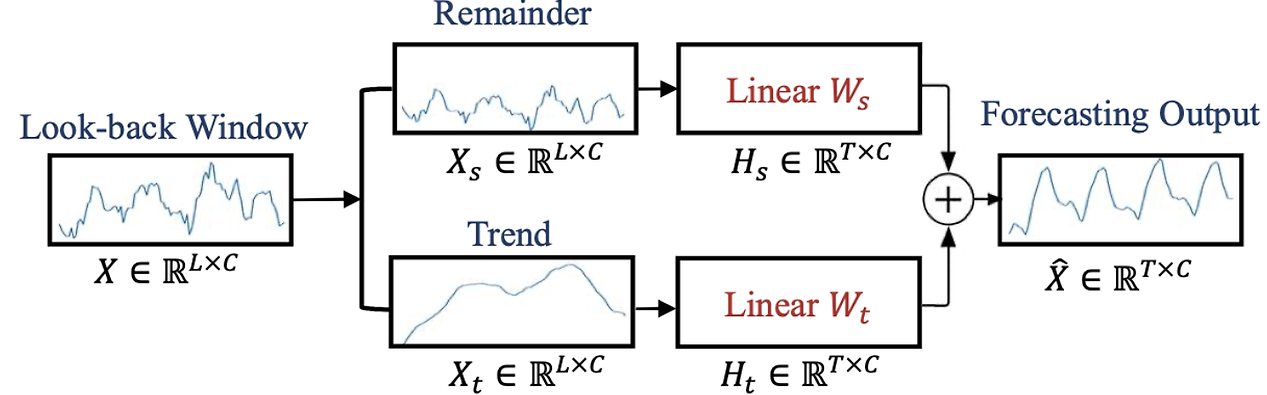
[평가 결과]
MAE : 0.0811
MSE : 0.0348
평가 결과, LSTM보다 LSTF가 더 높은 예측 성능을 보였으므로 상위 6개 종목을 선정하는데 LSTF 모델을 사용하기로 결정하였다.
4. Data Preprocessing (Trading)
4.1. Data Collection
- 대신 증권 API Creon을 이용하여 분봉 데이터를 최대 20만 개 수집
- 최근 분봉 데이터 15000개를 사용하여 학습 + 장 마감 후 당일 분봉 데이터 추가 학습
import win32com.client
import pandas as pd
class Creon:
def __init__(self):
self.obj_CpCodeMgr = win32com.client.Dispatch('CpUtil.CpCodeMgr')
self.obj_CpCybos = win32com.client.Dispatch('CpUtil.CpCybos')
self.obj_StockChart = win32com.client.Dispatch('CpSysDib.StockChart')
# 주식 차트 조회 메서드
def creon_7400_주식차트조회(self, code, date_from, date_to):
b_connected = self.obj_CpCybos.IsConnect
if b_connected == 0:
print("연결 실패")
return None
# 입력값 설정 및 요청
list_field_key = [0, 1, 2, 3, 4, 5, 8]
list_field_name = ['date', 'time', 'open', 'high', 'low', 'close', 'volume']
dict_chart = {name: [] for name in list_field_name}
self.obj_StockChart.SetInputValue(0, 'A'+code)
self.obj_StockChart.SetInputValue(1, ord('1')) # 0: 개수, 1: 기간
self.obj_StockChart.SetInputValue(2, date_to) # 종료일
self.obj_StockChart.SetInputValue(3, date_from) # 시작일
self.obj_StockChart.SetInputValue(5, list_field_key) # 필드
self.obj_StockChart.SetInputValue(6, ord('D')) # 'D', 'W', 'M', 'm', 'T'
self.obj_StockChart.BlockRequest()
# 데이터 수신 및 처리
status = self.obj_StockChart.GetDibStatus()
msg = self.obj_StockChart.GetDibMsg1()
print("통신상태: {} {}".format(status, msg))
if status != 0:
return None
cnt = self.obj_StockChart.GetHeaderValue(3) # 수신개수
for i in range(cnt):
dict_item = (
{name: self.obj_StockChart.GetDataValue(pos, i)
for pos, name in zip(range(len(list_field_name)), list_field_name)}
)
for k, v in dict_item.items():
dict_chart[k].append(v)
print("차트: {} {}".format(cnt, dict_chart))
return pd.DataFrame(dict_chart, columns=list_field_name)
creon = Creon()
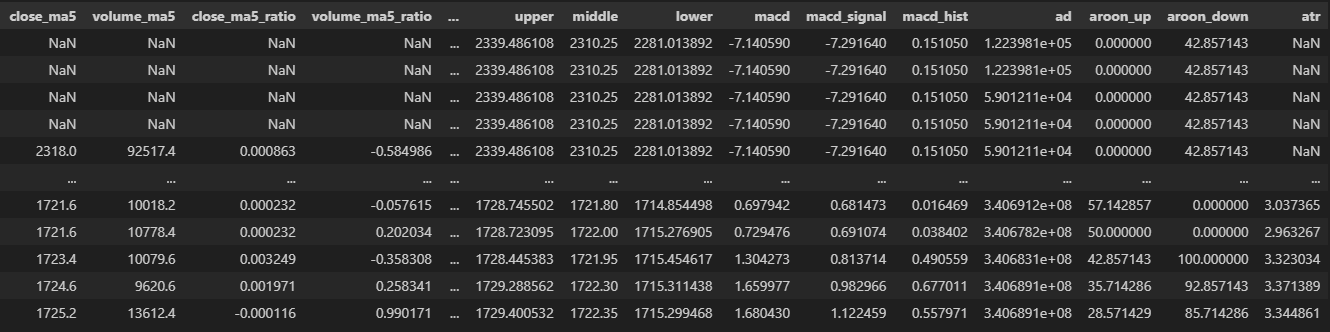
4.2. Data Preprocessing
- 종가와 거래량의 5, 10, 20, 60, 120 이동평균
- 시가-종가, 상한가-종가, 하한가-종가 비율 등
- Stochastic Oscilator : 과매수/과매도 상태 식별
- RSI : 과열이나 침체 국면 판단
- 볼린저밴드 : 주가의 변동생을 측정하고 상대적인 고점과 저점 파악
- 이동평균수렴확산 : 장단기 이동평균선으로 매매 모멘텀 추정
- 누적체적산 : 거래량을 고려하여 가격 움직임을 분석하고 주가 추세의 강도를 평가
- AROON : 가격의 상승 또는 하락 추세의 강도와 지속 시간 측정
- ATR : 가격의 움직임의 변동성 계산
5. RL Model
▶ 강화학습이란?
머신러닝의 한 종류로, 어떠한 환경에서 어떠한 행동을 했을 때 그것이 잘 된 행동인지 잘못된 행동인지 판단하고 보상 혹은 페널티를 줌으로써 스스로 반복 학습하는 기법
▷ 주식 투자도 어떠한 환경에서 매수, 매도, 홀드 등을 판단하는 문제로써 강화학습 적용 가능
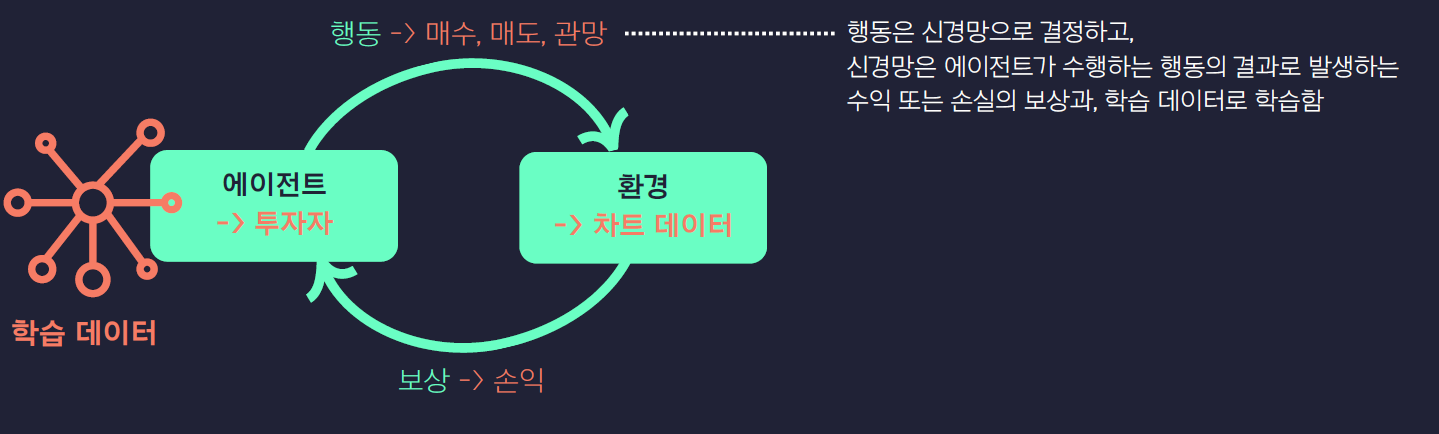
A2C (Advantage Actor - Critic) 알고리즘 사용
- Actor : 정책 경사 모델을 사용하여 현재 상태에서 어떤 행동을 취할 지 결정하는 역할
- Critic : Q - 러닝 모델을 사용하여 취해진 행동의 가치 평가
- Advantage 개념을 통해 예상되는 보상과 현재 정책에 따른 가치 함수 간의 차이를 이용해 액터의 정책 업데이트
for stock_code in args.stock_code:
# 차트 데이터, 학습 데이터 준비
chart_data, training_data = data_manager_3.load_data(
stock_code, args.start_date, args.end_date, ver=args.ver)
assert len(chart_data) >= num_steps
# 최소/최대 단일 매매 금액 설정
min_trading_price = 500
max_trading_price = 10000000
# 공통 파라미터 설정
common_params = {'rl_method': args.rl_method,
'net': args.net, 'num_steps': num_steps, 'lr': args.lr,
'balance': args.balance, 'num_epoches': num_epoches,
'discount_factor': args.discount_factor, 'start_epsilon': start_epsilon,
'output_path': output_path, 'reuse_models': reuse_models}
# 강화학습 시작
learner = None
if args.rl_method != 'a3c':
common_params.update({'stock_code': stock_code,
'chart_data': chart_data,
'training_data': training_data,
'min_trading_price': min_trading_price,
'max_trading_price': max_trading_price})
elif args.rl_method == 'a2c':
learner = A2CLearner(**{**common_params,
'value_network_path': value_network_path,
'policy_network_path': policy_network_path})
else:
list_stock_code.append(stock_code)
list_chart_data.append(chart_data)
list_training_data.append(training_data)
list_min_trading_price.append(min_trading_price)
list_max_trading_price.append(max_trading_price)
if args.rl_method == 'a3c':
learner = A3CLearner(**{
**common_params,
'list_stock_code': list_stock_code,
'list_chart_data': list_chart_data,
'list_training_data': list_training_data,
'list_min_trading_price': list_min_trading_price,
'list_max_trading_price': list_max_trading_price,
'value_network_path': value_network_path,
'policy_network_path': policy_network_path})
[테스트 영상]
6. Github
RLTrader" target="_blank" rel="noopener" data-mce-href="http://RLTrader">http://RLTrader
GitHub - skier-song9/bitamin1213_trading: BitaMin, data analysis & data science assosiation, 12th and 13th joint project.
BitaMin, data analysis & data science assosiation, 12th and 13th joint project. - skier-song9/bitamin1213_trading
github.com