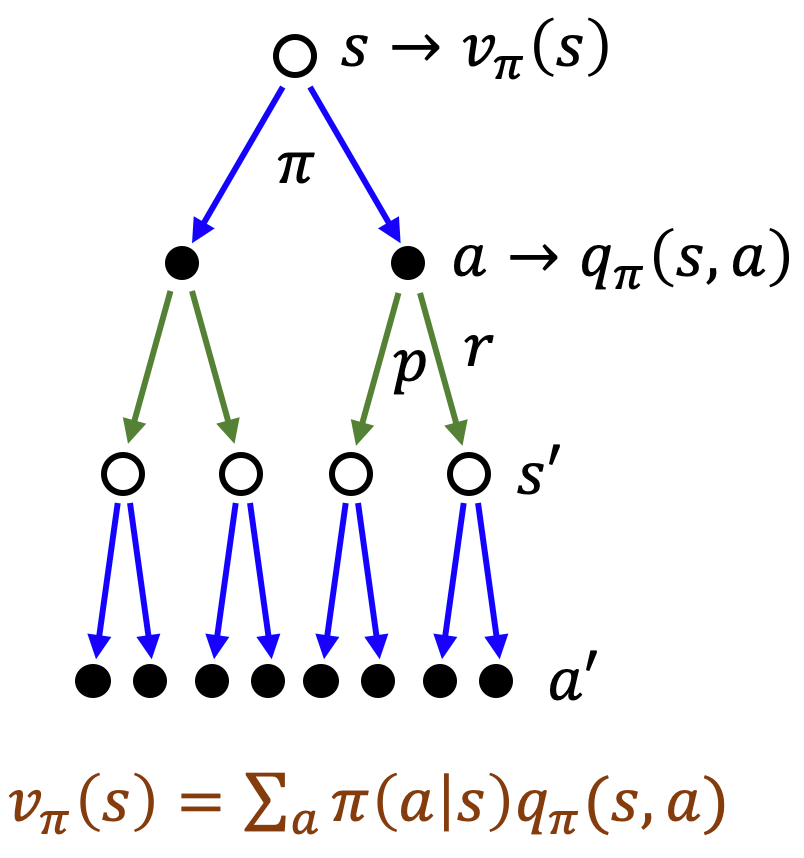
Value Functions (가치 함수) 가치 함수는 각 상태 $s$(또는 상태-행동 쌍$(s; a)$)의 퀄리티를 측정합니다. 이때, 정책 $\pi$에 대한 기대 보상은 $G_t$를 따른다. State-Value Function (상태-가치 함수) $v_{\pi}(s)$ 정책 $\pi$를 따랐을 때 특정 상태 $s에서 시작하는 기대 반환을 나타냄 $v_{\pi}(s) = \mathbb{E}_{\pi} \left[ G_t | S_t = s \right]$ Action-Value Function (행동-가치 함수) $q_{\pi}(s,a)$ 상태 $s$에서 행동 $a$를 취하고 이후 $\pi$를 따라갔을 때의 기대 반환을 나타냄 $q_{\pi}(s, a) = \mathbb{E}_{\pi} \left[ G..