이번 겨울방학 때 카이스트 금융공학 연구실에서 인턴을 할 수 있는 기회가 생겼다. 학기 중에 이력서랑 자기소개서 등 정리하면서 나름 열심히 준비하여 신청했는데 합격했을 때는 정말 감개무량하였다. 소중한 기회가 주어진 만큼 열심히 참여해야겠다고 다짐하였다.
오늘 소개할 프로젝트는 연구실에서 진행한 첫번째 프로젝트이다.
Github
Github Link" target="_blank" rel="noopener" data-mce-href="http://Github Link">http://Github Link
GitHub - taekyounglee1224/GCN_Spillover: KAIST FE Lab Internship : Can financial return forecasts be improved by unlocking addit
KAIST FE Lab Internship : Can financial return forecasts be improved by unlocking additional information within the data, without utilizing additional data? - taekyounglee1224/GCN_Spillover
github.com
1. Introduction
이 연구는 데이터 자체에 잠재된 정보를 추출하여 추가적인 외부 데이터 세트를 통합하지 않고도 금융 수익률 예측을 향상시킬 수 있는 가능성을 조사한다. 이 분석은 글로벌 금융 지수 간의 파급 효과를 측정하는 데 초점을 맞추고, Graph Convolution Network(GCN) 및 Graph Attention Network(GAT)와 같은 고급 그래프 임베딩 방법론을 탐구한다.
이 연구는 시가총액이 가장 높은 15개 글로벌 금융 지수의 파급 효과에 초점을 맞춰 고급 그래프 기반 방법론의 사용 가능성을 조사한다. 이 접근법은 데이터 효율성과 복잡한 상호의존성을 모델링하는 능력을 강조하면서 재무 예측에서 그래프 기반 기법의 미개발 잠재력을 강조한다.
2. Data & Methodology
2.1. Data Collection
글로벌 지수의 종가 및 거래량 데이터는 2004년 1월 1일부터 2024년 12월 31일까지의 기간 동안 Investing.com 웹사이트에서 주요 주가지수 목록을 크롤링하여 수집한 것으로, Yahoo Finance에서 크롤링을 통해 수집하였다. 그 결과, 총 41개의 글로벌 지수가 수집되었다. 수집된 지수 중 16개는 수집 기간 중 결측값이 많아 제외되어 총 25개의 지수가 남았고, 남은 25개 지수 중 종가와 시장 거래량의 누적 합으로 계산한 시가총액을 기준으로 총 15개 지수를 선정하였다. 수익률 예측을 용이하게 하기 위해 종가 데이터를 일일 수익률 데이터로 변환하였다.
2.2. Graph Data Generation
원래 테이블 형식의 데이터는 그래프 임베딩을 위해 그래프 구조의 데이터 집합으로 변환되었다. 그래프에서 노드는 개별 주가지수를 나타내고, 에지는 이들 간의 상관관계를 나타낸다. 상관 계수의 절댓값이 0.3 이상인 에지만 유지했는데, 이 임계값은 보통 이상의 상관 관계를 가진 의미 있는 관계만 포함하도록 하여 노이즈를 줄이고 그래프 구조의 품질을 향상시키기 때문이다.

위의 이미지와 같은 그래프가 총 41개 생성되었고, (왜 41개인지는 후술) 이 41개의 그래프 모형에 대해 각각 임베딩 결과를 도출하였다.
2.3. Benchmark Models
이 연구는 그래프 기반 임베딩을 활용하여 원시 데이터에만 의존하는 벤치마크 모델에 비해 예측 성능이 향상되는지 살펴본다. 벤치마크 모델로 사용한 모델은 다음과 같다.
1) Random Forest Regressor (RF)
2) Gradient Boost Regressor (XGBoost)
3) Multi-Layer Perceptron (MLP)
4) K-Neighbors Regressor (KNN)
5) Support Vector Regressor (SVM)
3. Graph Embedding Models
그래프는 노드 집합(꼭지점이라고도 함)과 이러한 노드를 연결하는 가장자리로 구성된 데이터 구조이다. 일반적으로 G = (V, E)로 정의되며, 여기서 V는 노드 집합을 나타내고 E는 노드 쌍을 연결하는 에지 집합을 나타낸다. GNN은 일반적으로 메시지 전달 메커니즘을 사용해 각 노드의 임베딩을 계산하는데, 여기에는 인접 노드와의 관계를 활용해 노드의 임베딩을 업데이트하는 작업이 포함된다.
3.1. GCN
그래프 컨볼루션 네트워크(GCN)는 노드의 특성과 그래프의 구조를 모두 활용해 그래프 데이터를 학습하는 모델이다. 노드의 임베딩은 노드 자체의 특징과 이웃 노드의 특징을 결합하여 업데이트된다.
$$H^{\left(l+1\right)}=\sigma\left(\hat{A}H^{\left(l\right)}W^{\left(l\right)}\right)\ =\ \sigma\left(D^{-\frac{1}{2}}\widetilde{A}D^{-\frac{1}{2}}H^{\left(l\right)}W^{\left(l\right)}\right)$$
Forward Pass
- Input은 데이터의 초기 형태인 $H^{\left(0\right)}\in R^{N\times F}$이다.
- $\widetilde{A\ }=\ A\ +\ I$, 는 그래프의 인접 행렬로, 자체 루프가 추가된 형태이다.
- 행렬의 $A_{ij}=\left\{0,1\right\}$ 요소는 노드 i와 노드 j 사이에 에지가 있는지를 나타낸다.
- D는 대각선 행렬 $(D_{ii}=\sum_{j} A_{ij})$을 말한다.
Backward Pass
이 단계에서는 weight matrix를 다음과 같은 방식을 사용해서 업데이트한다.
$$\mathcal{L}=\frac{1}{N}\sum_{i=1}^{N}\mathrm{Loss}\left(\widehat{y_i},y_i\right)$$
3.2. GAT
그래프 주의 네트워크(GAT)는 그래프 신경망에 주의 메커니즘을 도입한 것이다. GCN에서와 같이 모든 이웃을 동일하게 취급하는 대신 GAT는 인접 노드에 서로 다른 주의 가중치를 할당하여 모델이 특징 집계 중에 가장 관련성이 높은 이웃에 집중할 수 있도록 한다.
GAT 모델의 주요 목적은 새로운 노드 특징 집합을 이전 입력 $h=\left\{h_1^\prime,h_2^\prime,\cdots,h_n^\prime\right\}$에서 출력 $h^\prime=\left\{h_1,h_2,\cdots,h_n\right\}$로 일반화하기 위한 것이다.
이 과정을 위한 Attention Coefficient는 다음과 같이 계산된다
$$e_{ij}=\mathrm{LeakyReLU}\left(a^T(Wh_i\ ||\ Wh_j)\right)$$
이 Attention Coefficient는 Softmax Function을 통해서 정규화된다.
GAT 모델은 멀티 헤드 주의 메커니즘을 사용해 모델의 안정성과 표현력을 향상시킨다. 최종 레이어에서는 노드 분류와 같은 작업을 위해 주의 헤드를 연결하지 않고 평균을 낸다.
$$h_i^\prime={||}_{k=1}^K\sigma\left(\sum_{j\in\mathcal{N}\left(i\right)}{\alpha_{ij}^{\left(k\right)}W^{\left(k\right)}h_j}\right)$$
4. Experimental Design
기준 실험은 15개의 지표를 원래 표 형식으로 사용하여 수행했다. 예측에는 3.1.1에 표시된 5가지 모델이 사용되었고, 테스트는 총 41개의 다른 세그먼트에서 수행되었다. 각 테스트 세트는 6개월의 Train Set와 6개월의 Test Set으로 구성되었다.

예측 목적은 다음 날의 수익률을 예측하는 것이었다(1일 예측). 특징 변수의 경우, 모든 인덱스 열의 시간 단계 1에서 N-1(여기서 N은 각 테스트 기간의 총 행 수)까지의 데이터를 사용하였다. 각 실험의 목표 변수는 데이터 누출을 방지하기 위해 시간 단계 2에서 N까지의 특정 인덱스 열 $i(i\ =\ 1,2,\ \cdots,\ 15)$의 반환 데이터로 설정했다. 이 과정은 각 실험마다 목표 인덱스 i를 변경하여 반복했으며, 결과의 robustness를 위해 각 목표에 대해 30회의 반복을 수행하였다. 모델 성능을 종합적으로 평가하기 위해 모든 목표 지표에 대해 평균 RMSE와 MAE를 계산하였다.
그래프 기반 실험은 GCN 및 GAT 모델을 사용하여 수행하였는데, 임베딩은 이전에 구축된 그래프 데이터 세트를 기반으로 각 노드와 에지에 대해 생성되었다. GCN 모델과 GAN 모델 모두 처음 두 개는 숨겨진 레이어로, 마지막 레이어는 임베딩 레이어로 총 세 개의 레이어로 구성되었다. GAT 모델의 경우, 주의 헤드의 수도 추가되었다.
5. Results
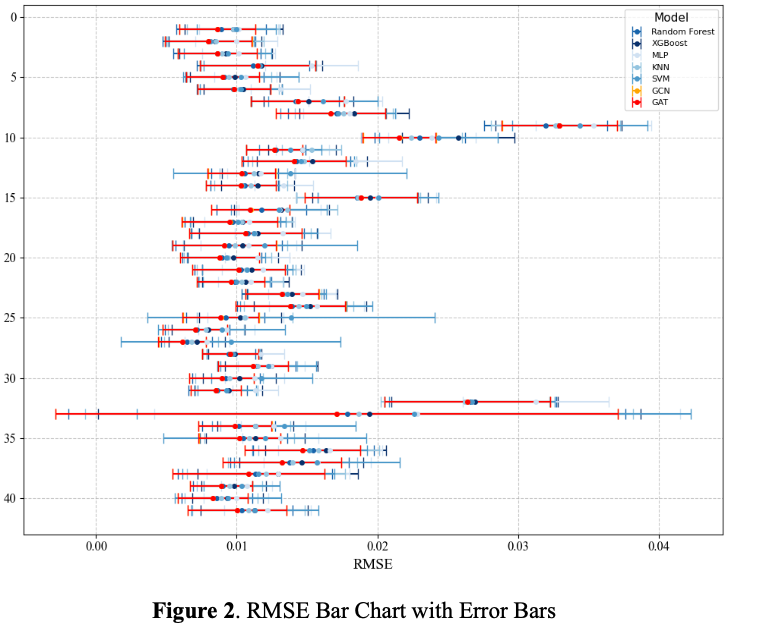

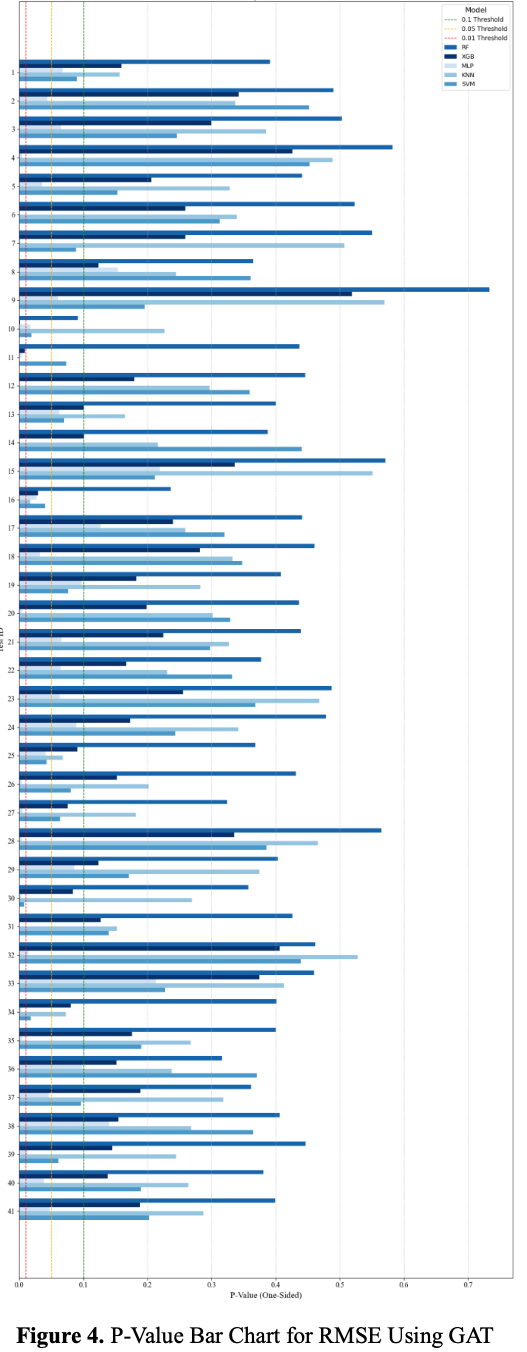
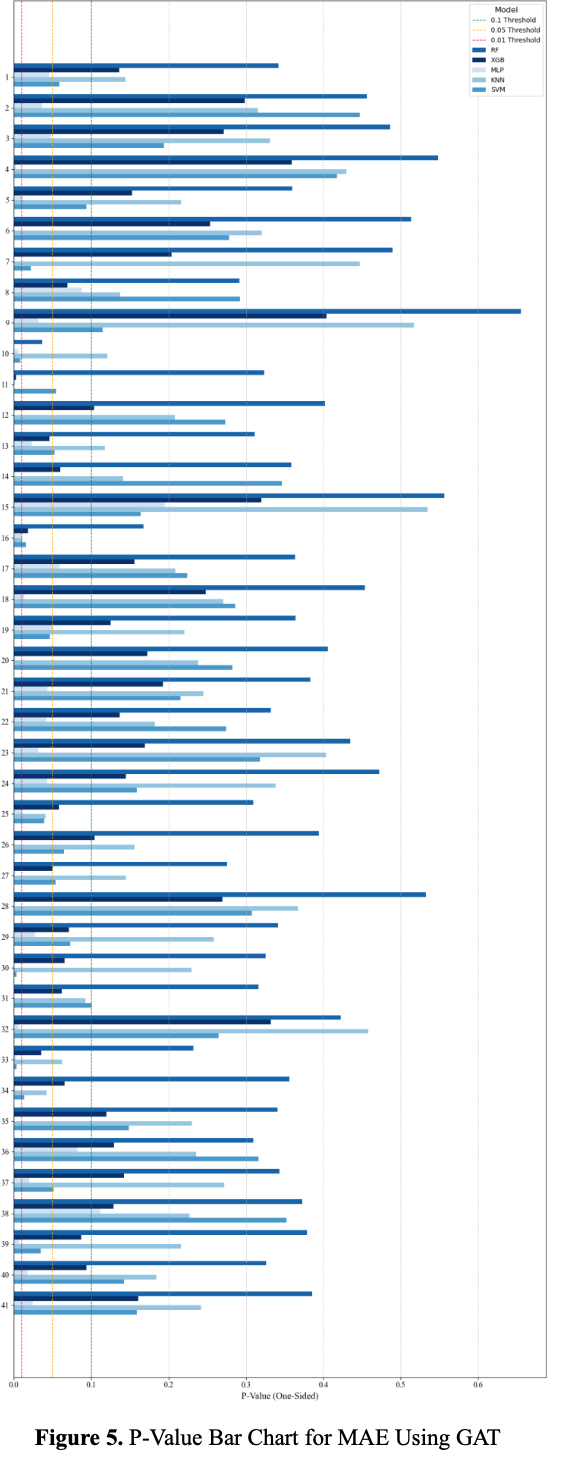


6. Discussion and Conclusion
이 연구는 그래프 기반 모델이 financial crisis나 안정적인 시장 상황에서 좋은 성과를 보임을 증명한다. 그래프 기반 모델은 안정된 시장에서도 다양한 시나리오에서 안정적이고 다재다능한 성능을 유지한다. 추가적인 외부 데이터 없이도 높은 예측 정확도를 제공하는 능력은 데이터 효율성을 강조한다. 그러나 상대적으로 높은 계산 비용으로 인해 신중한 예측 성능과 리소스 사용의 균형을 맞추려면 시장 역학에 기반한 신중한 모델 선택이 필요하다.