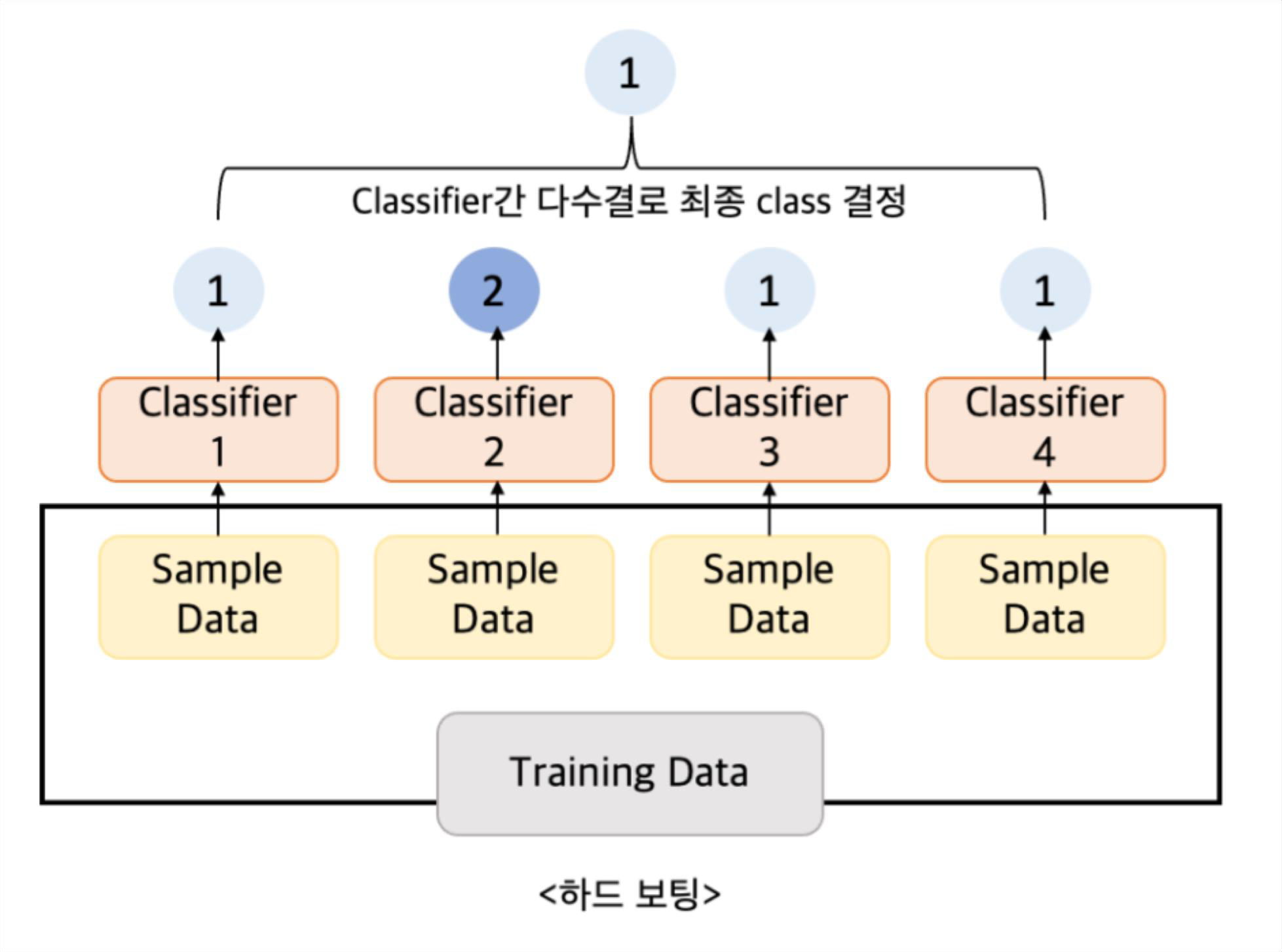
앙상블이란?앙상블 기법이란 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 더 좋은 최종 예측을 도출하는 기법을 말한다. 앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 예측 신뢰성을 높이는 것이다. 1. Voting앙상블 기법에는 여러 가지 알고리즘이 있는데, 우선 보팅(Voting) 알고리즘부터 살펴보자. 보팅이란 서로 다른 알고리즘을 가진 분류기가 동일한 데이터셋을 가지고 각자 예측을 수행하여 최종 결과를 결정하는 방식이다. 이때, 각 분류기가 예측한 결과를 가지고 '투표' 방식으로 최종 결과를 결정하기 때문에 Voting이라고 불린다. 이 투표 방식에는 두 가지 방식이 있는데, Hard Voting과 Soft Voting이 있다.1.1. Hard Votin..