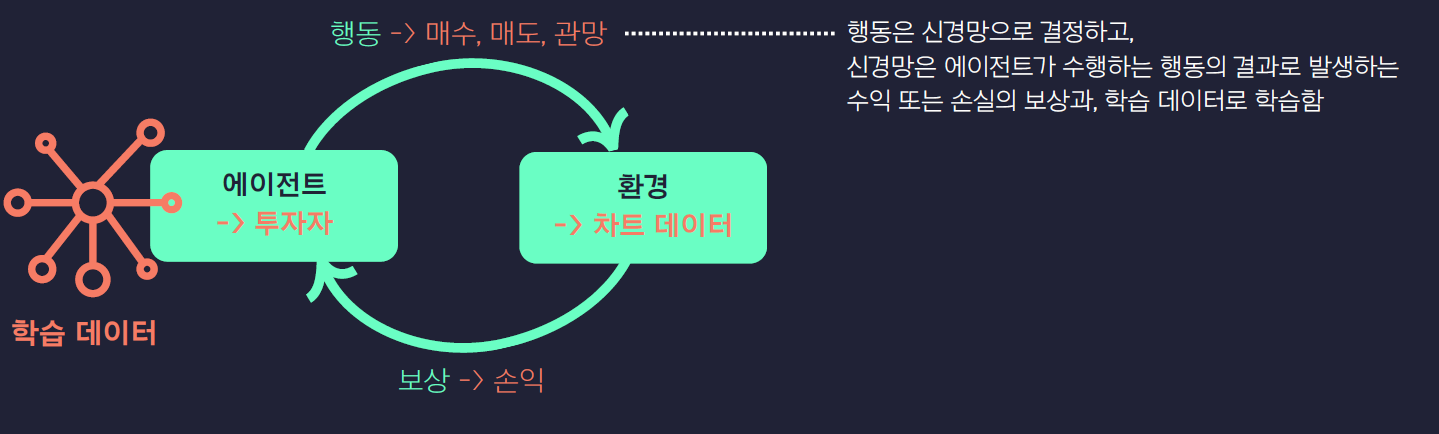
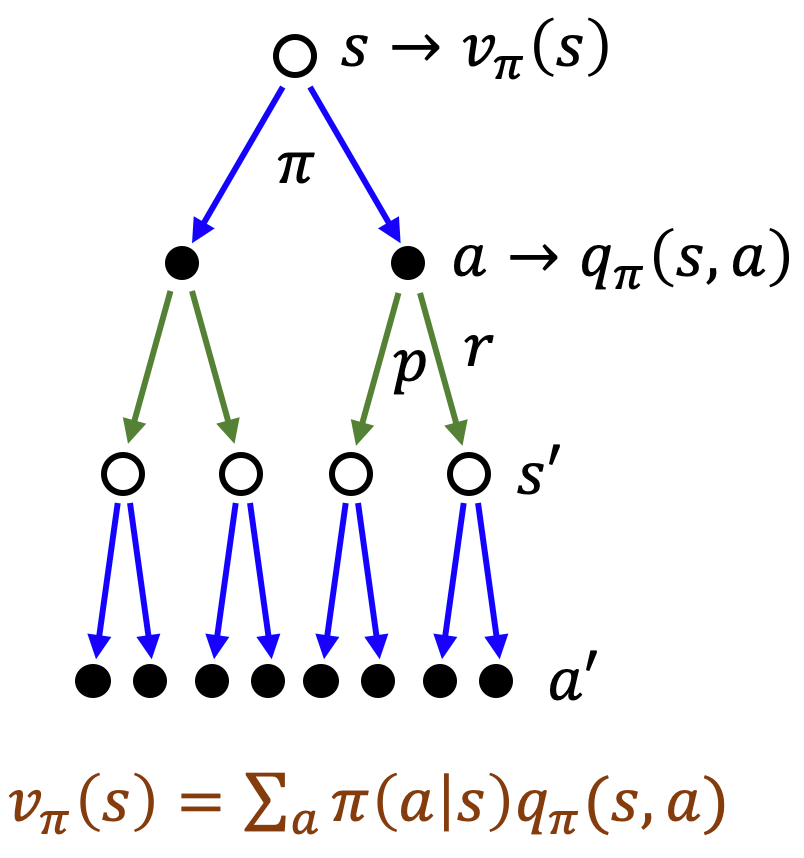
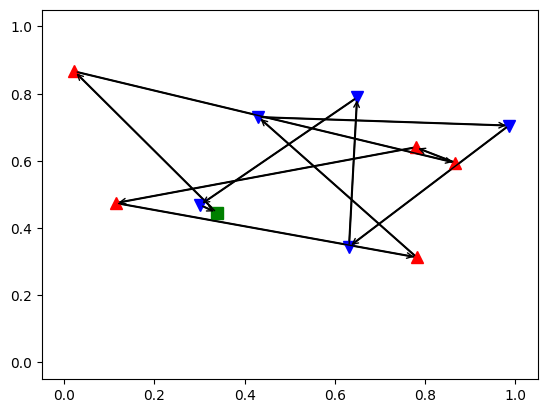
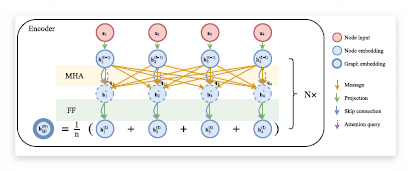
View Paper" target="_blank" rel="noopener" data-mce-href="http://View Paper">http://View Paper Learning to Solve Vehicle Routing Problems with Time Windows through Joint AttentionMany real-world vehicle routing problems involve rich sets of constraints with respect to the capacities of the vehicles, time windows for customers etc. While in recent years first machine learning models have been dev..